














Davies Mark
Γλώσσα
Αγγλική
Ημερομηνία
28/06/2013
Διάρκεια
23:37
Εκδήλωση
Ημερίδα για τη δημιουργία και ανάλυση των διαχρονικών σωμάτων κειμένων
Χώρος
Κεντρικό κτίριο Πανεπιστημίου Αθηνών
Διοργάνωση
Τομέας Γλωσσολογίας - Τμήμα Φιλολογίας - Εθνικό και Καποδιστριακό Πανεπιστήμιο Αθηνών
Κατηγορία
Γλωσσολογία / Γλωσσικά Θέματα
Ετικέτες
διαχρονικά σώματα κειμένων, Corpus of Historical American English
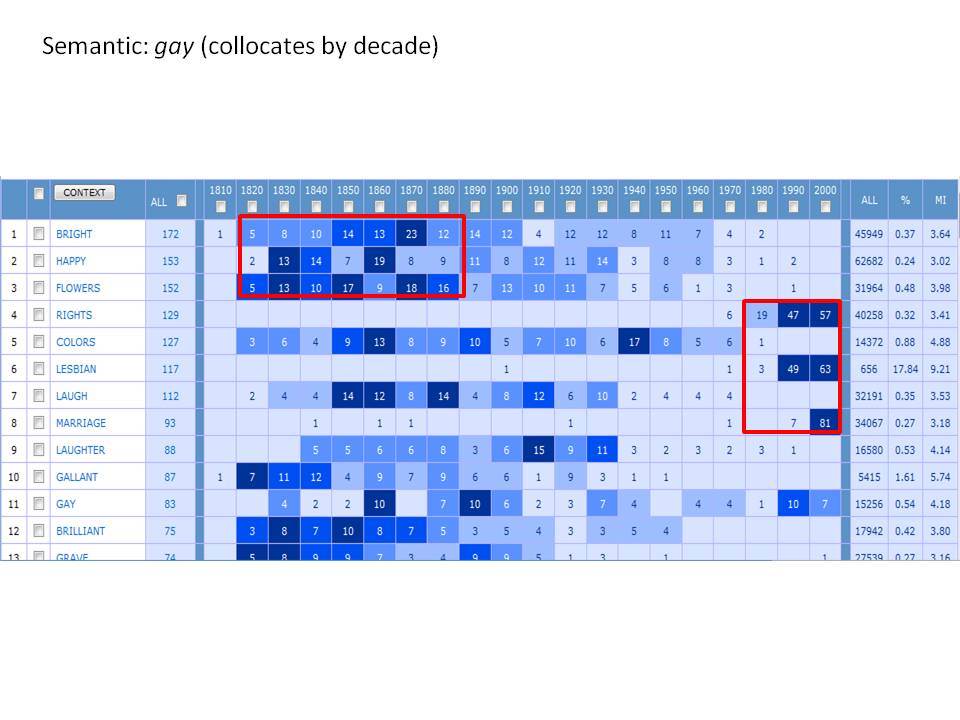
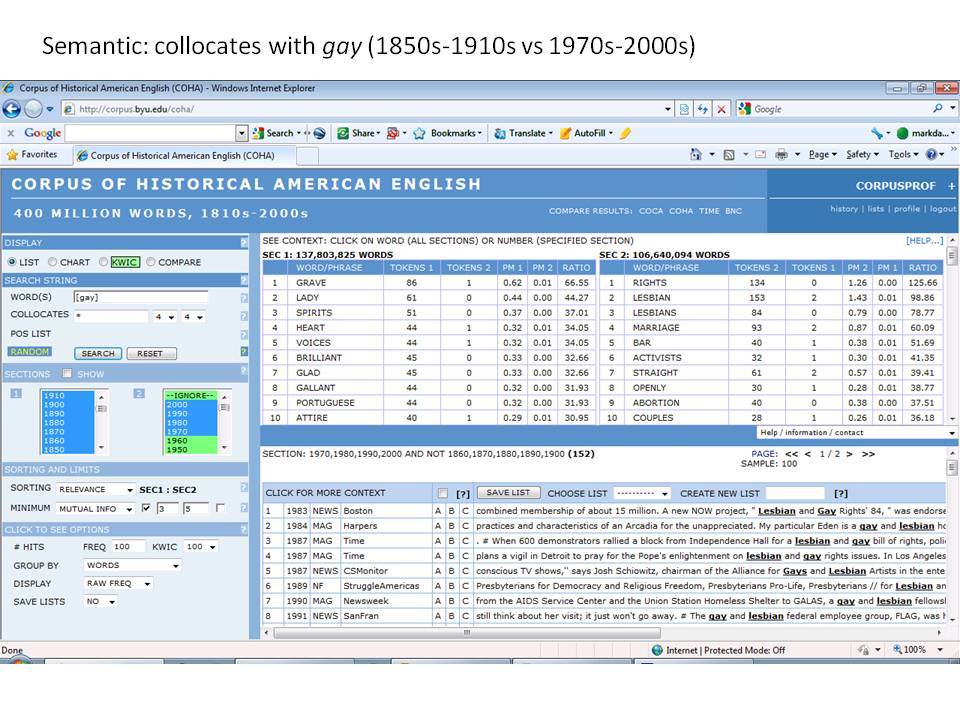
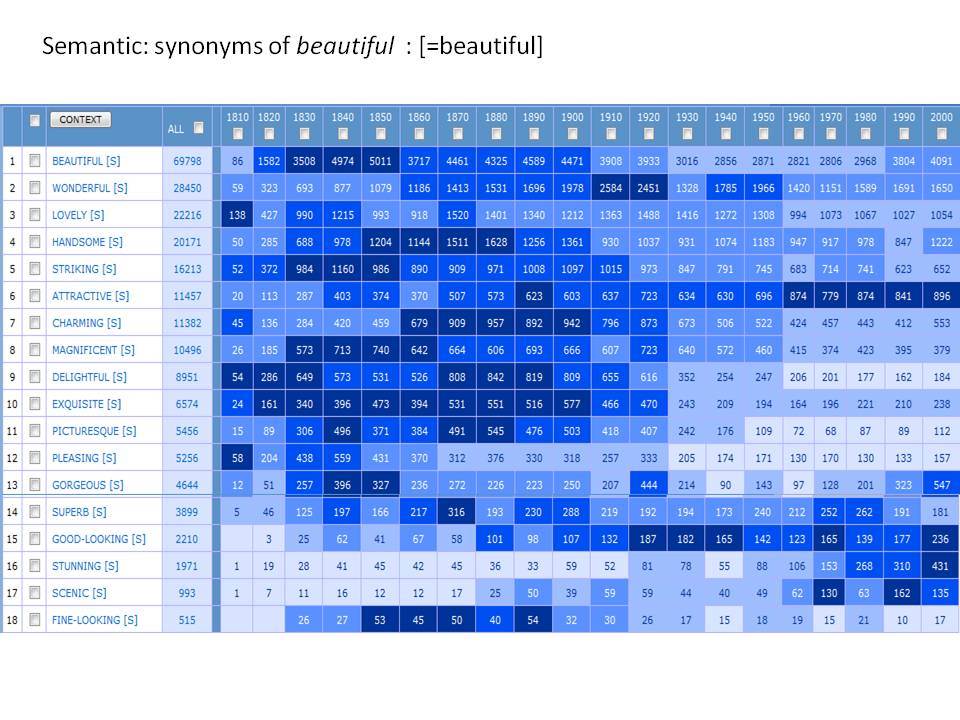
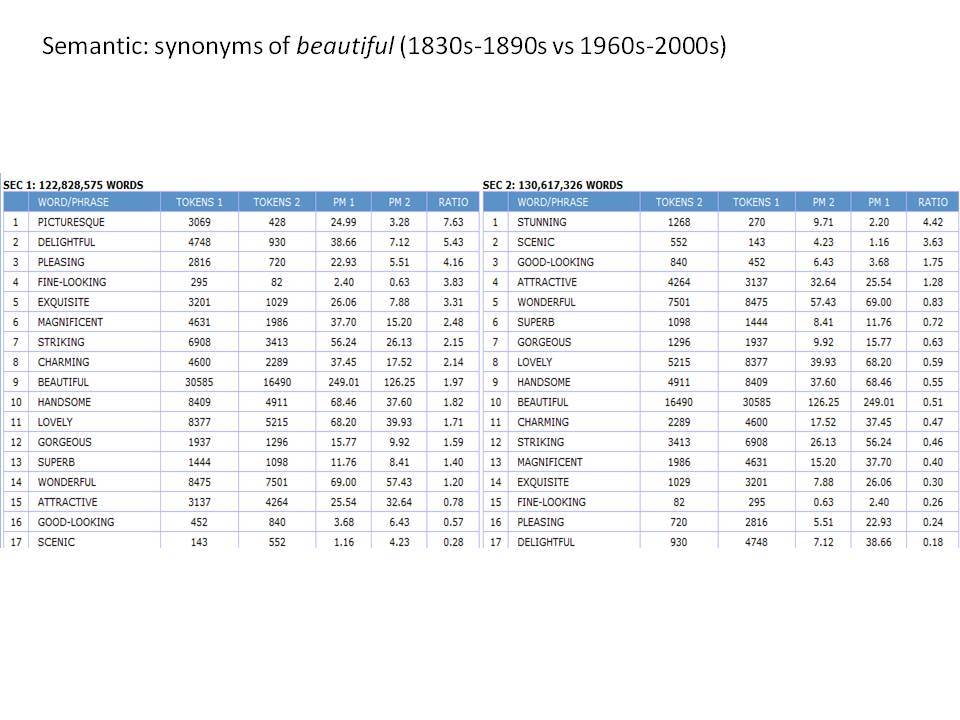
Εξετάζοντας ένα ευρύ φάσμα γλωσσικών αλλαγών με το Corpus of Historical American English (1810-2009)
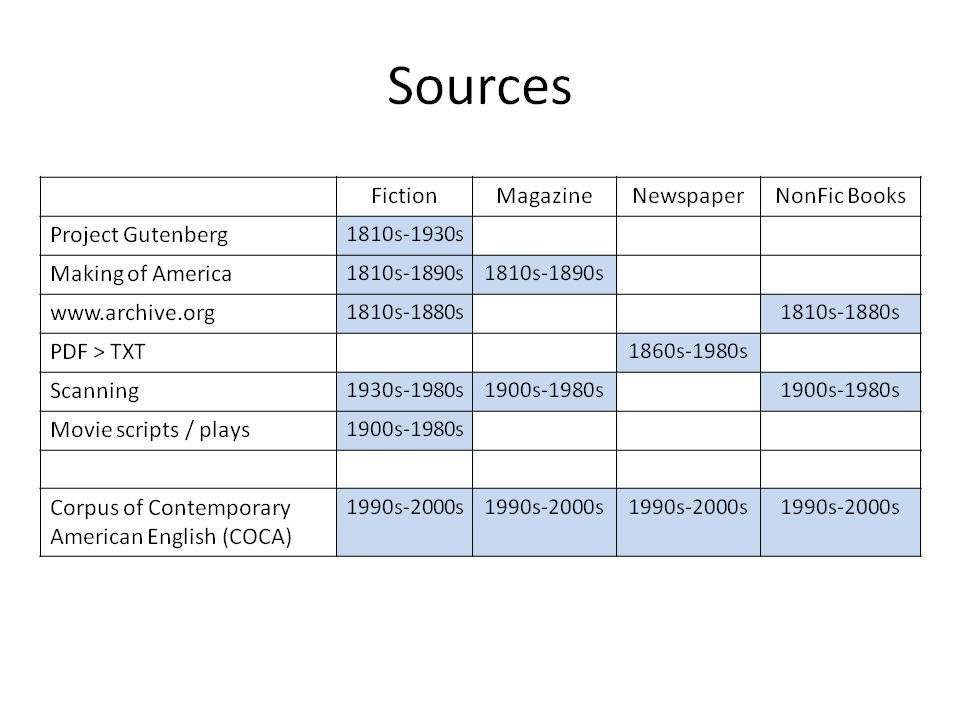
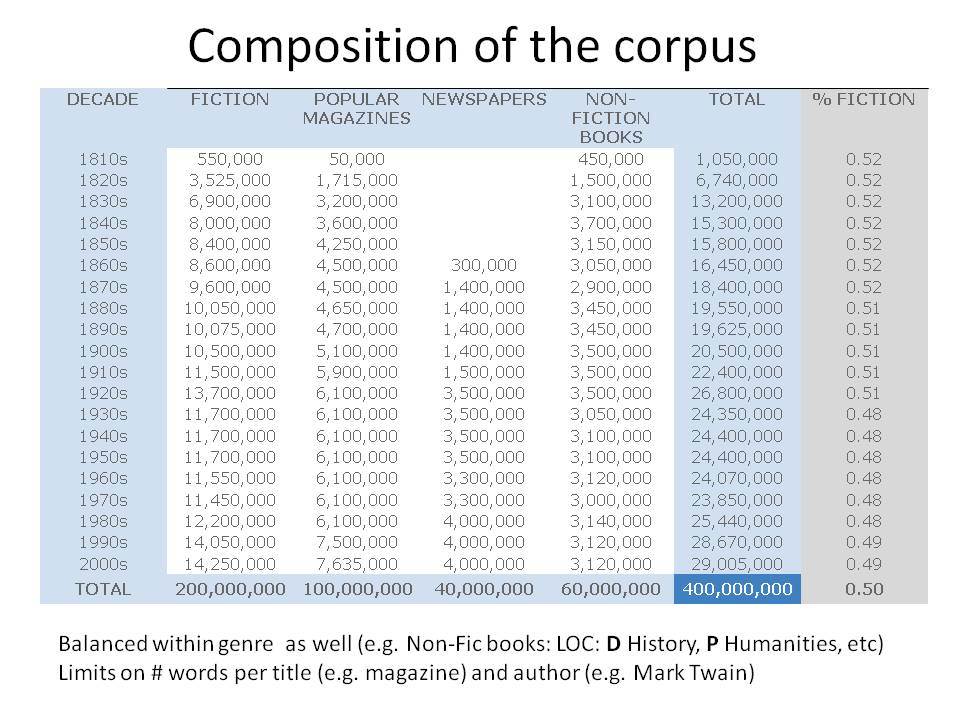
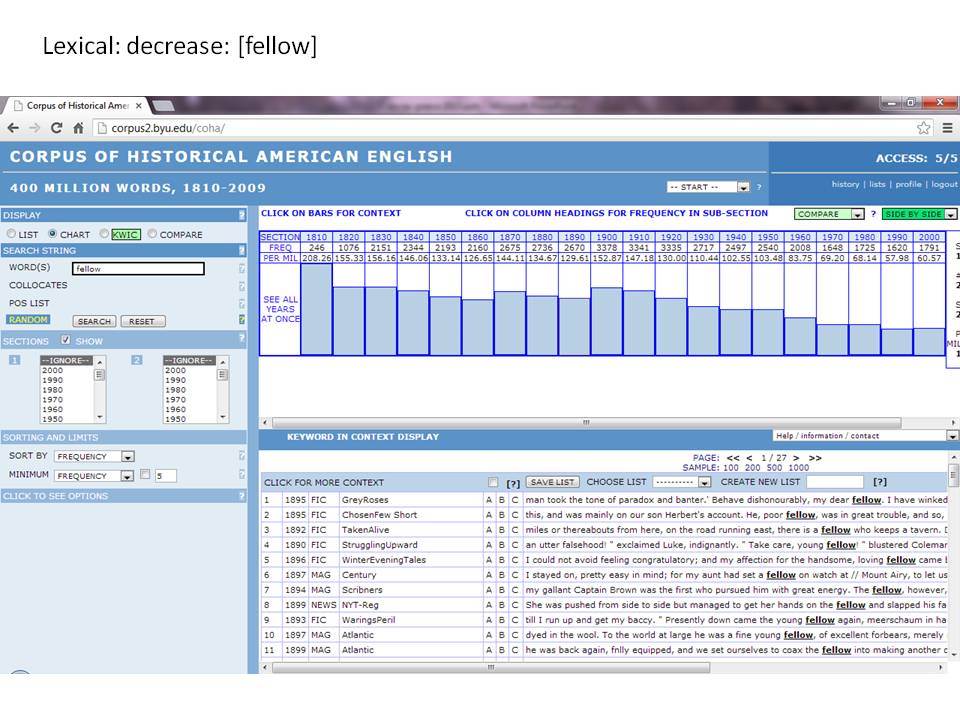
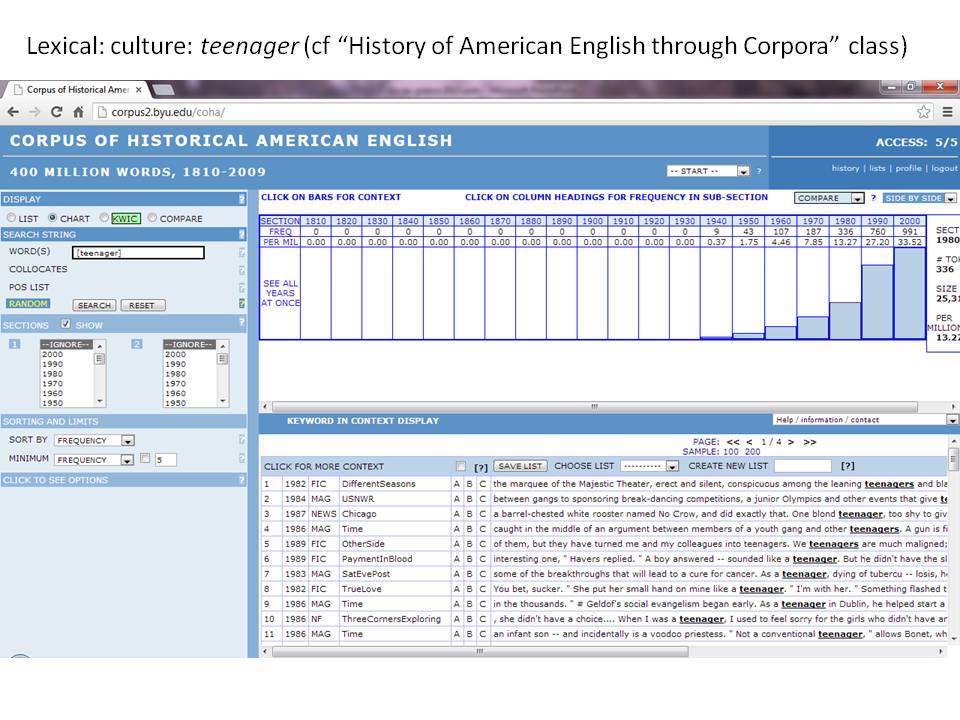
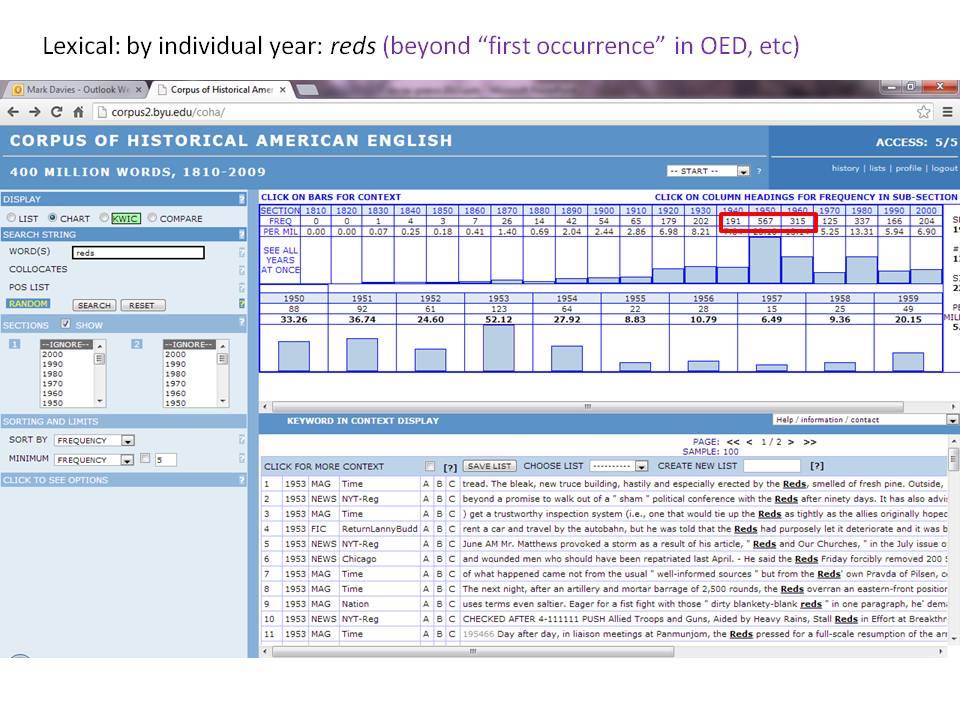
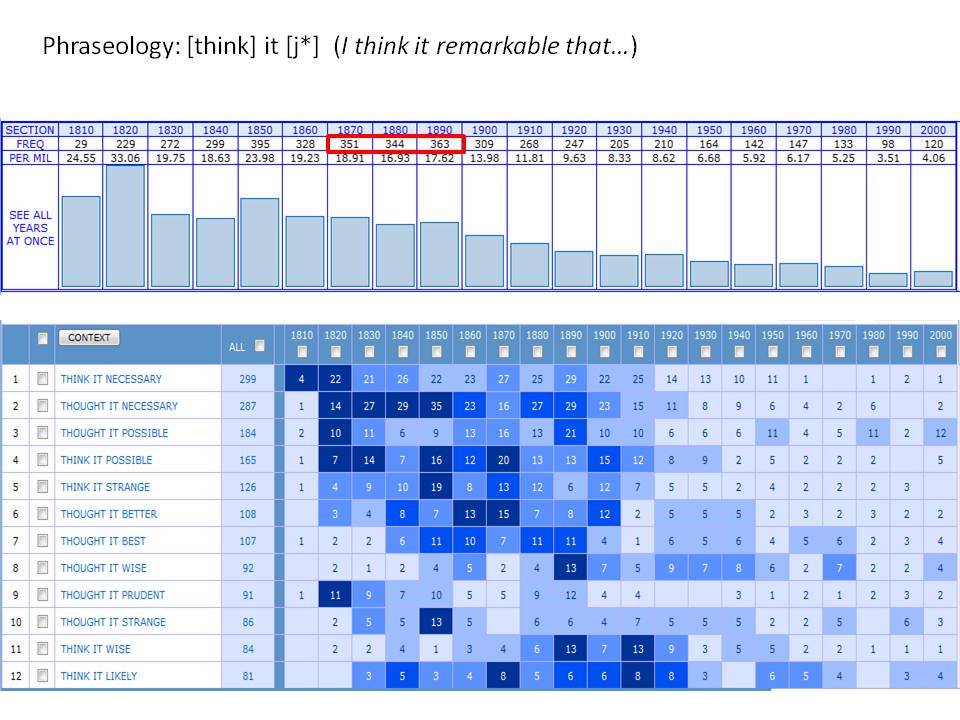
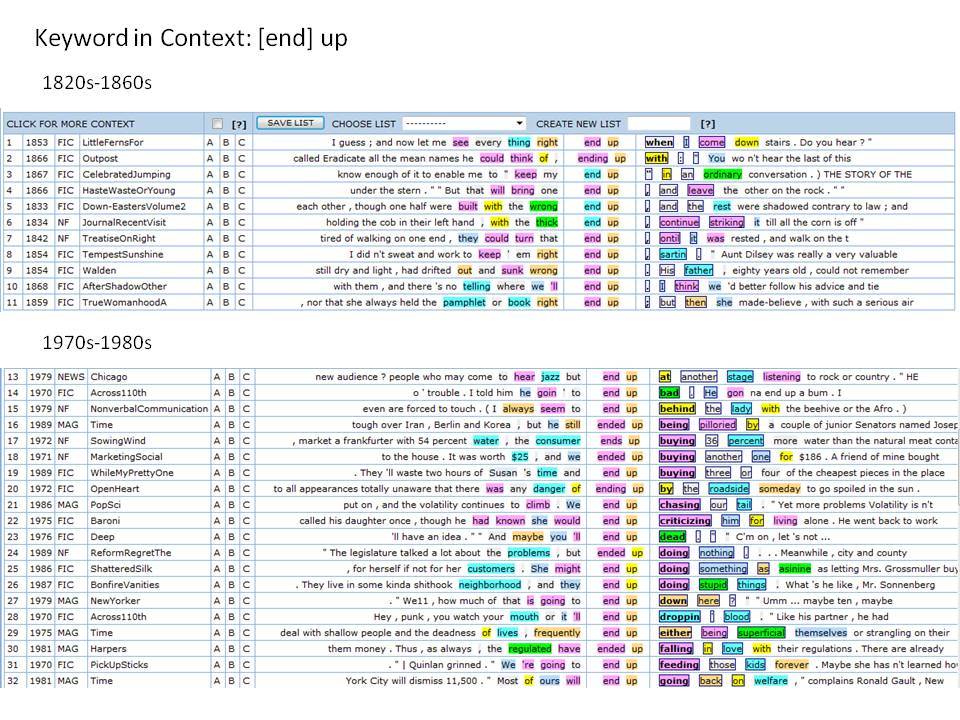
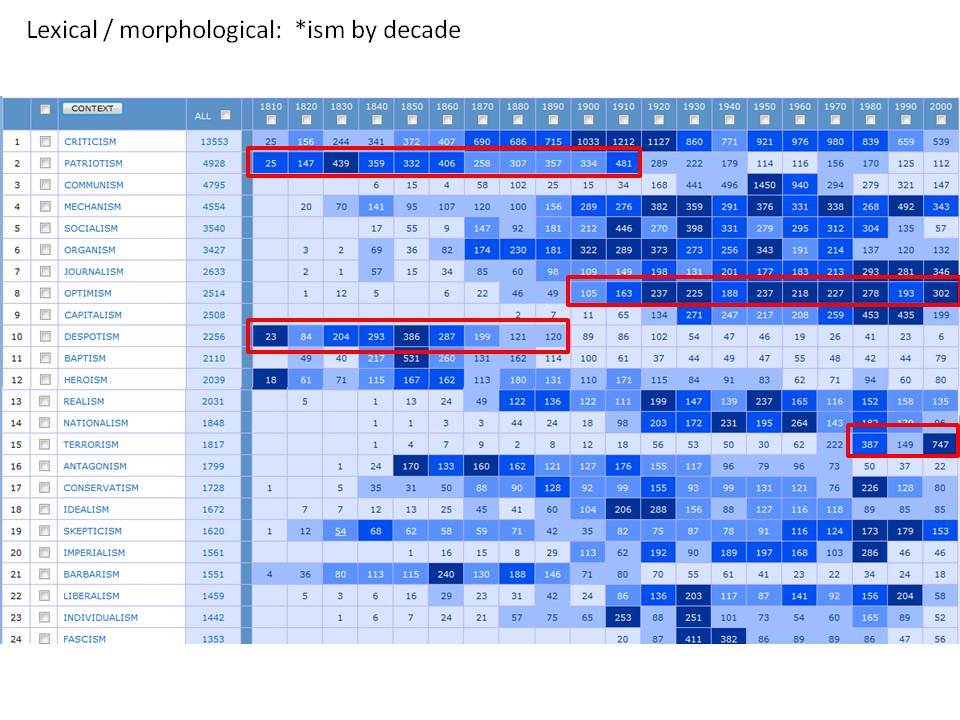
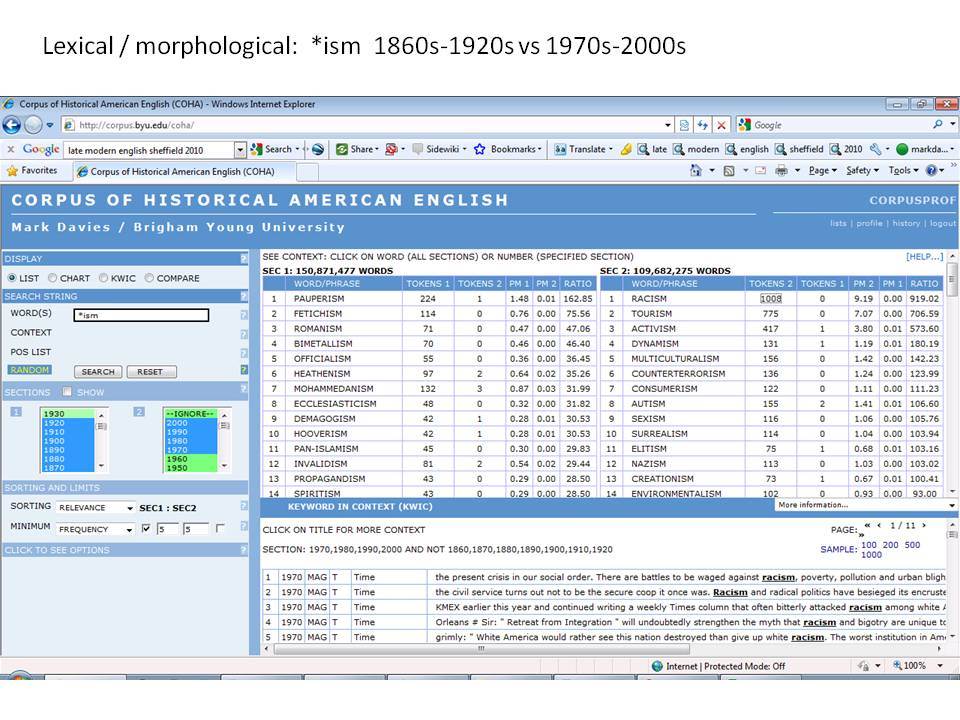
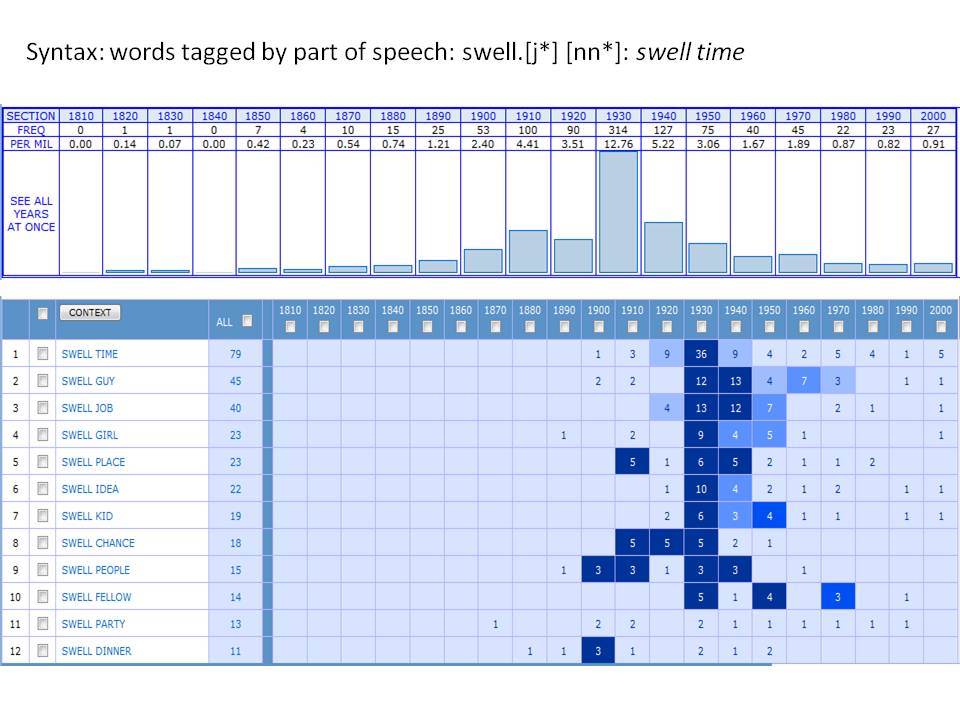
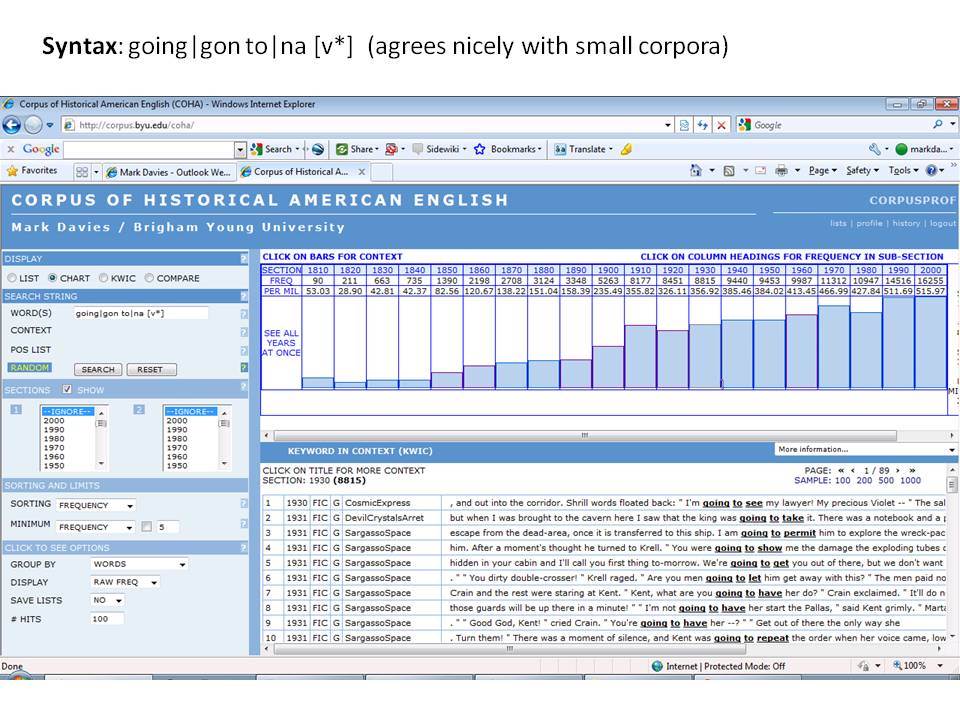
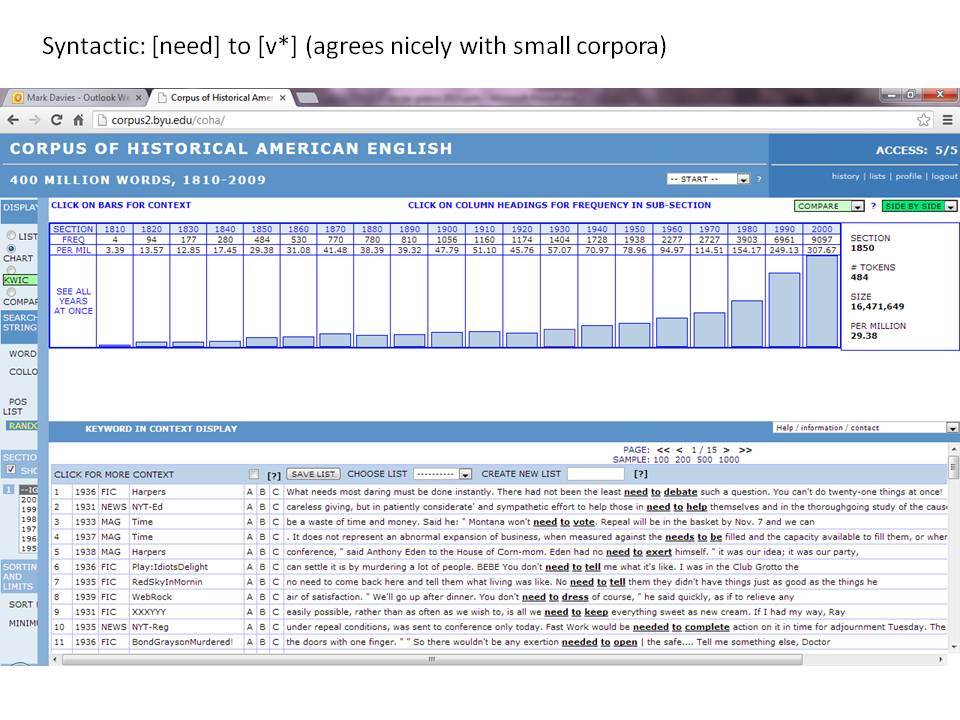
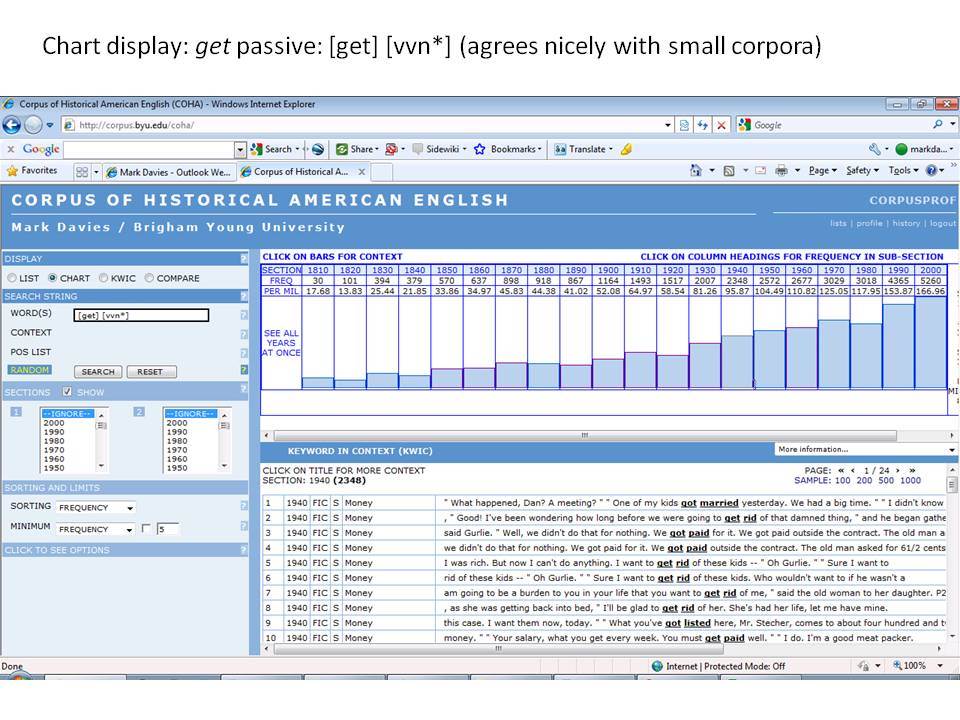
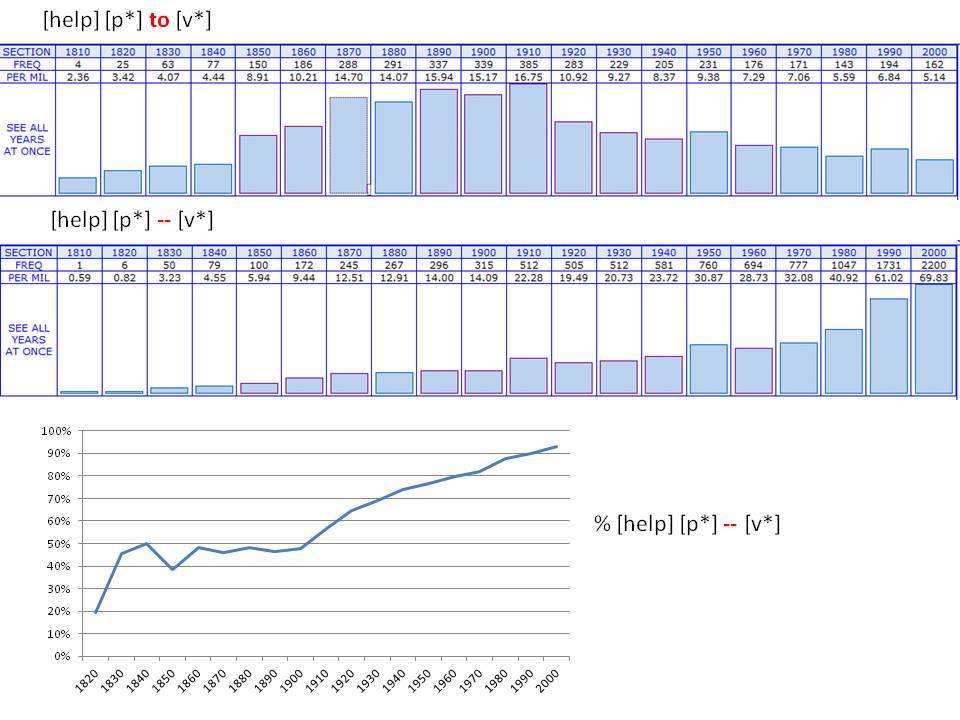
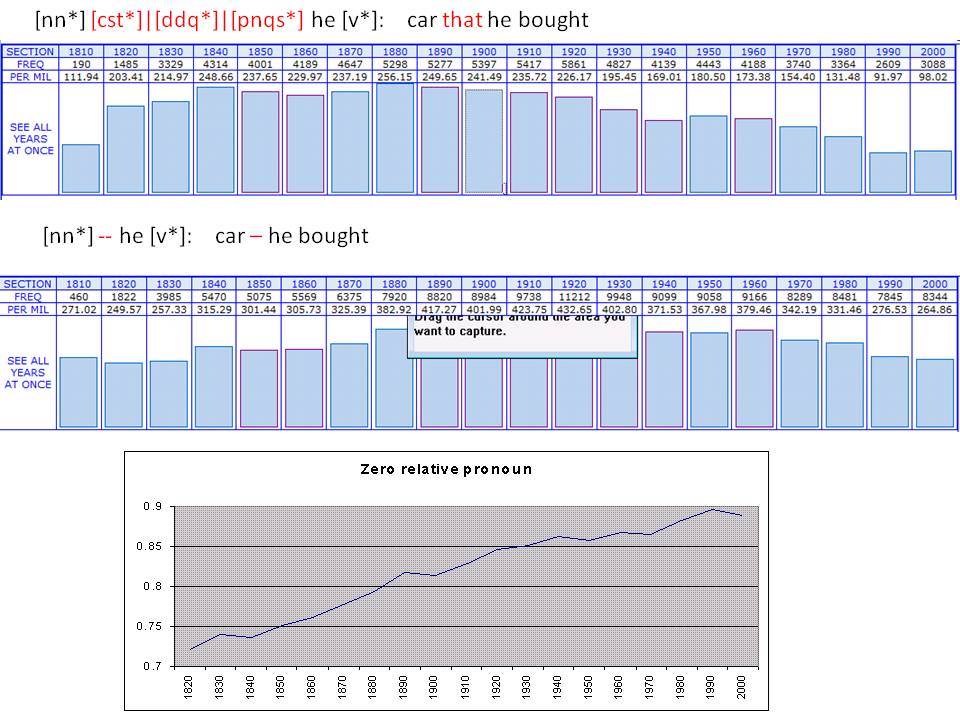
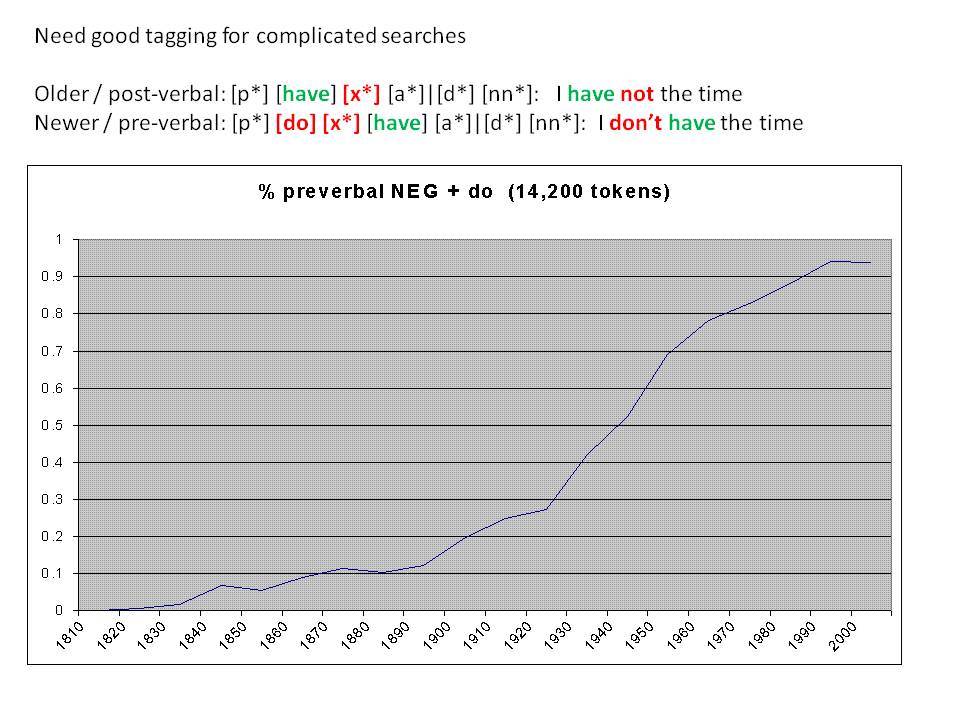
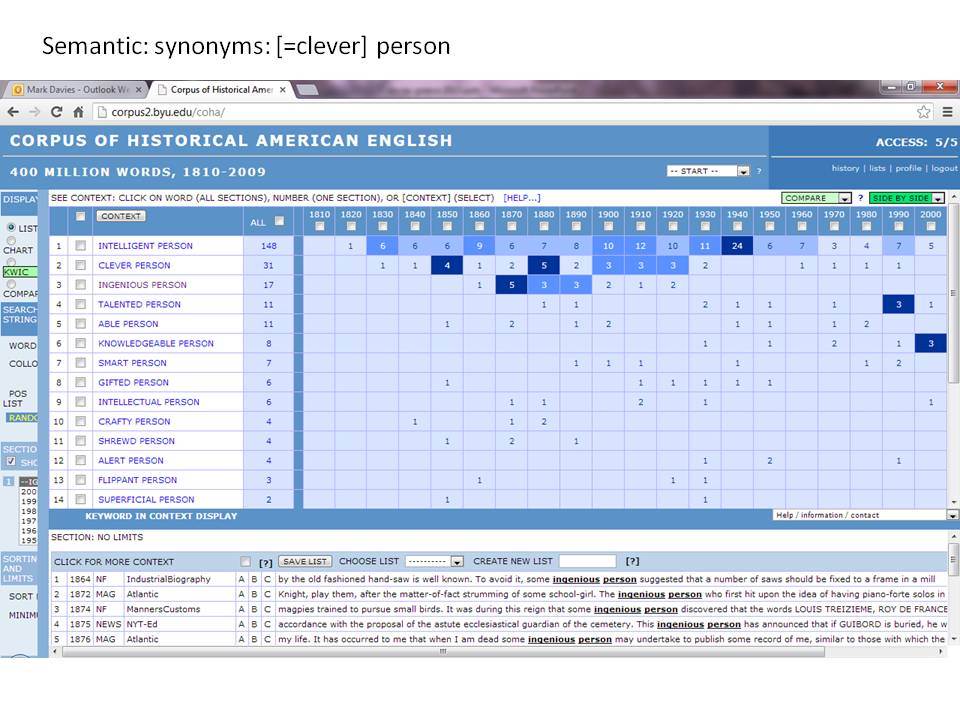
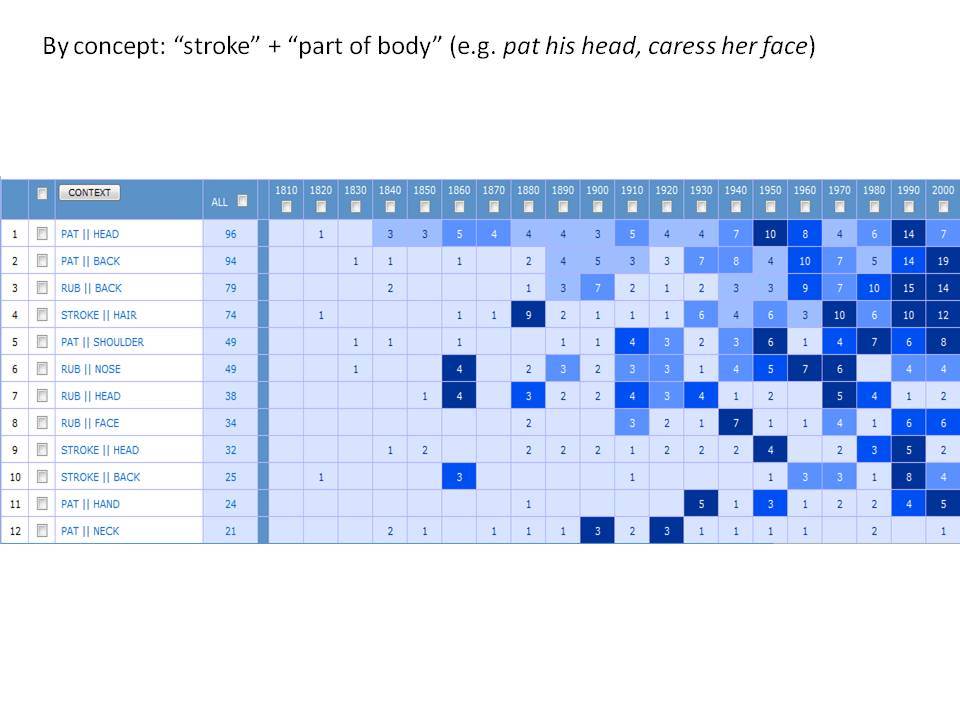
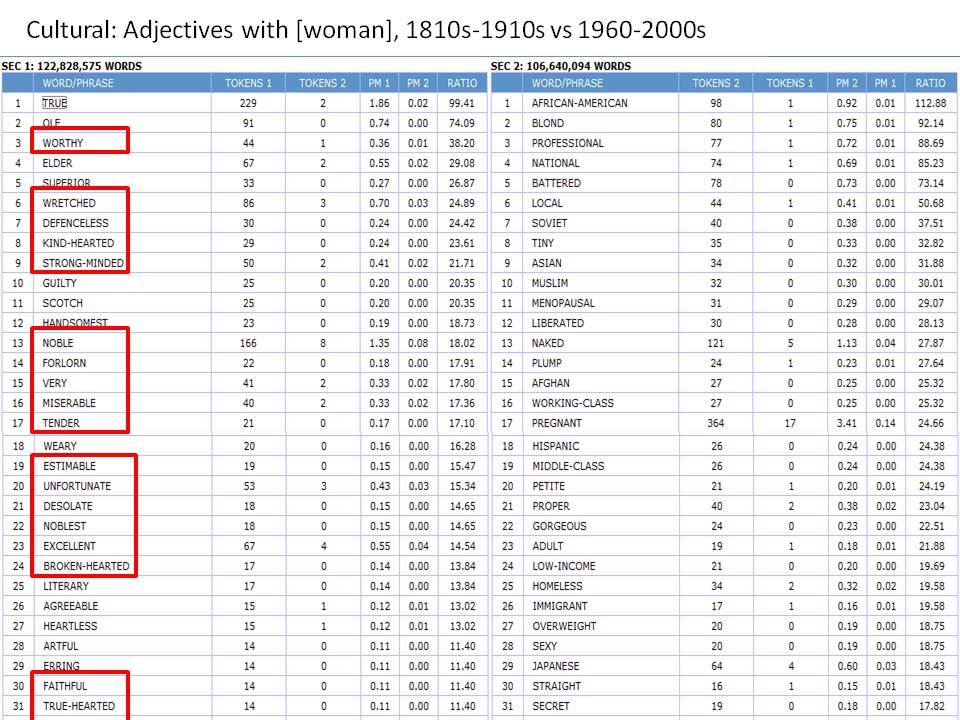
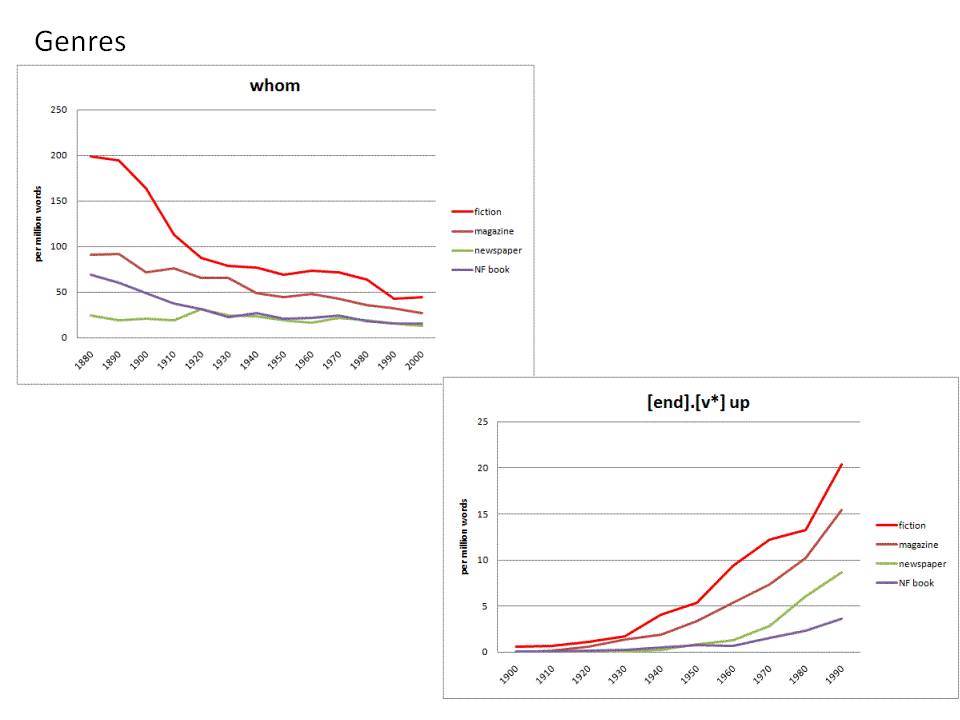
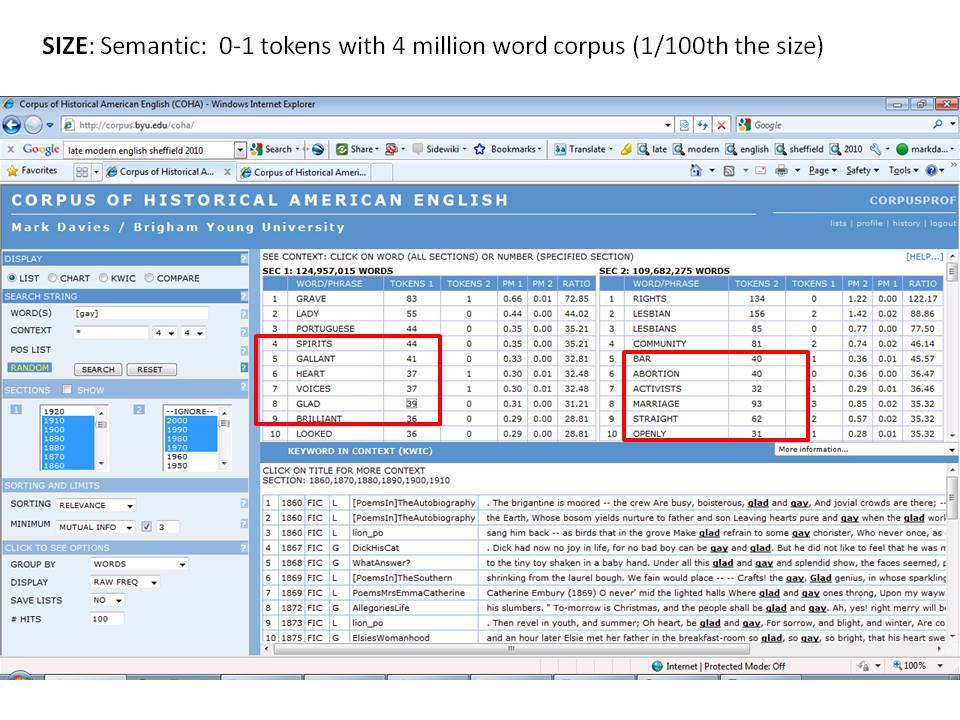
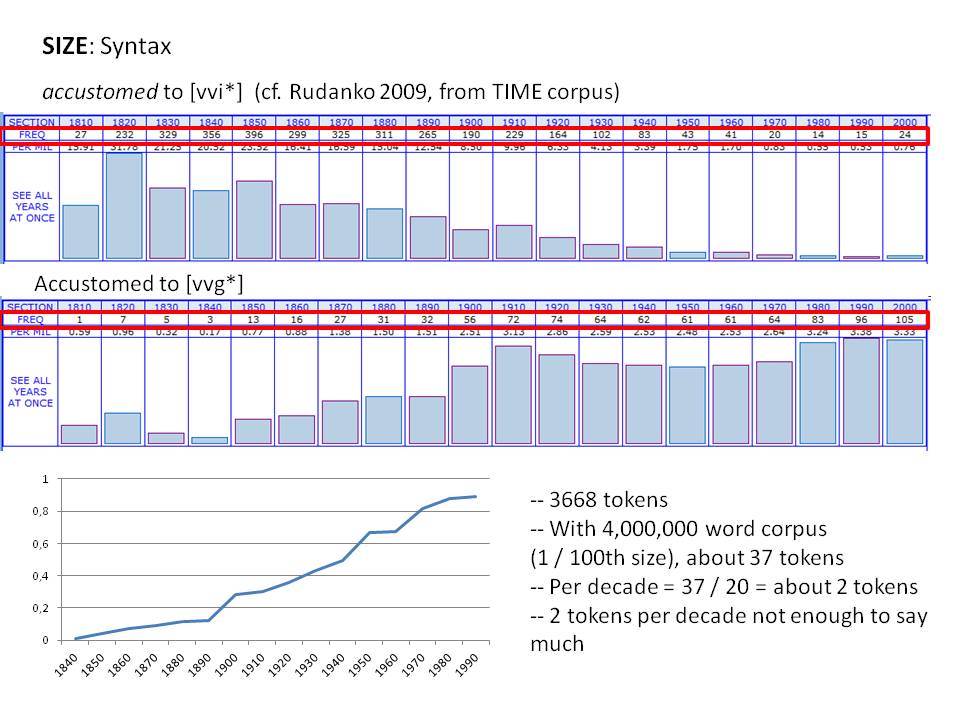
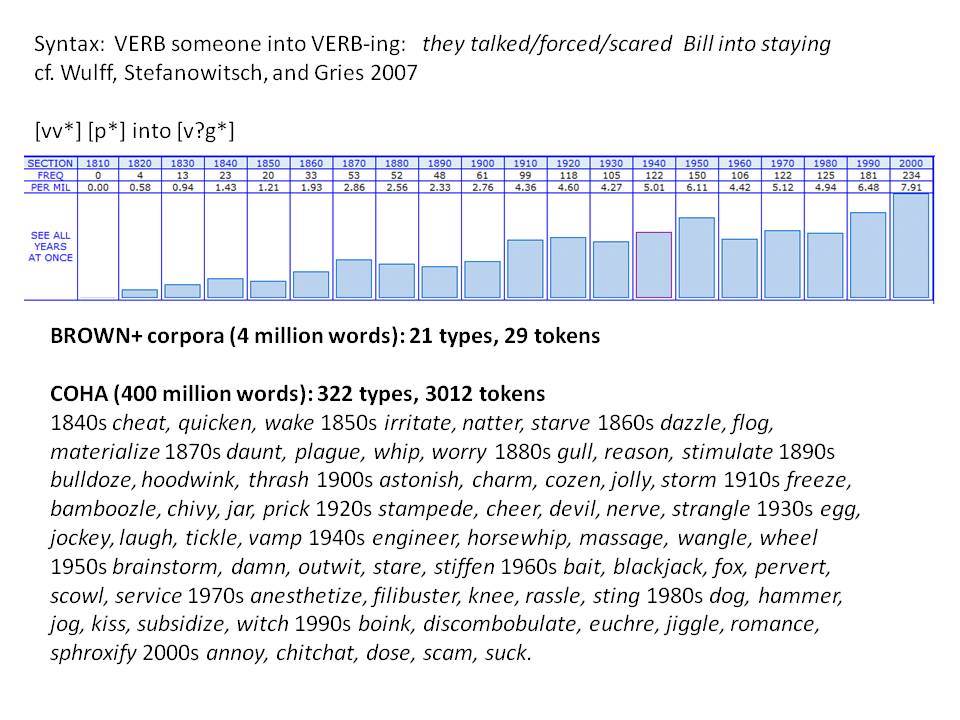
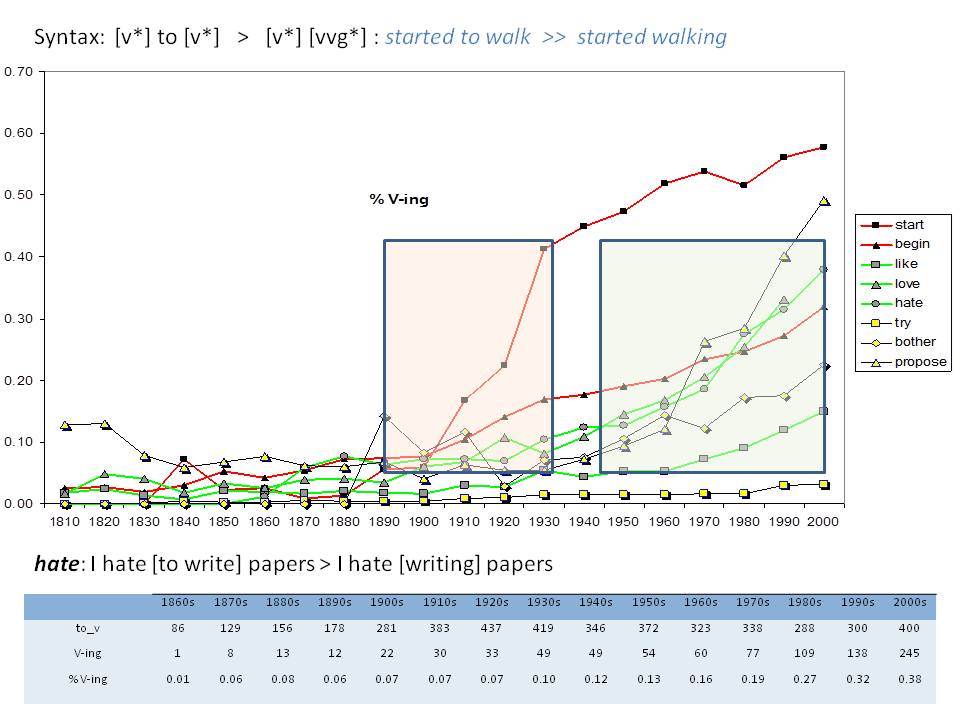
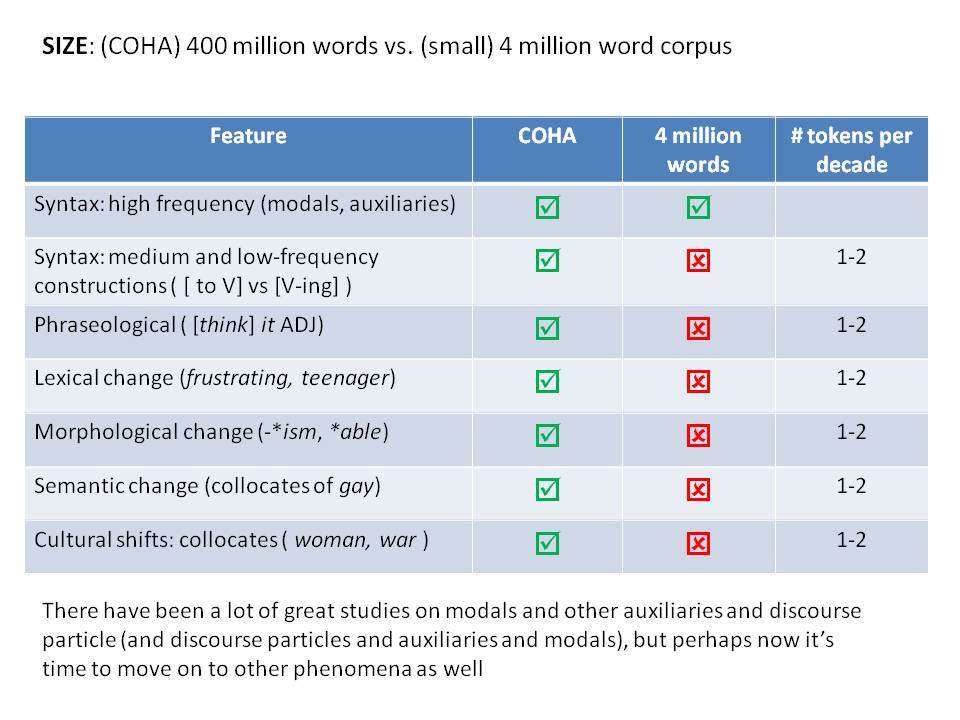
Το Corpus of Historical American English (COHA; http://corpus.byu.edu/coha), που αποτελείται από 400 εκατομμύρια λέξεις, περιέχει πάνω από 100.000 κείμενα από τη δεκαετία του 1810 έως τη δεκαετία του 2000, κάτι που το καθιστά περίπου 100 φορές μεγαλύτερο από κάθε άλλο δομημένο σώμα κειμένων ιστορικών Αγγλικών. Το σώμα κειμένων διαθέτει ισορροπία ανάμεσα στα κειμενικά είδη της πεζογραφίας, των εκλαϊκευτικών περιοδικών, των εφημερίδων και των μη λογοτεχνικών βιβλίων για κάθε δεκαετία του σώματος κειμένων και διατηρεί την ίδια ισορροπία από δεκαετία σε δεκαετία (καθώς και στις υποκατηγορίες αυτών των κειμενικών ειδών). Εξαιτίας του μεγέθους του, παρέχει δεδομένα για πολλά φαινόμενα που δεν μπορούν να μελετηθούν με μικρά σώματα κειμένων 2-4 εκατομμυρίων λέξεων, όπως η οικογένεια σωμάτων κειμένων Brown ή το ARCHER. Στην παρουσίασή μου αναφέρομαι σε πολλά παραδείγματα τέτοιων αλλαγών σε λεξιλογικό, μορφολογικό, φρασεολογικό, συντακτικό και σημασιολογικό επίπεδο.
Η ανακοίνωση πραγματοποιήθηκε στο πλαίσιο ημερίδας που διοργανώθηκε από το πρόγραμμα «Διαχρονικό Σώμα Ελληνικών Κειμένων του 20ού αιώνα» (Greek Corpus 20, http://greekcorpus20.phil.uoa.gr/), το οποίο συγχρηματοδοτείται από το Ευρωπαϊκό Κοινωνικό Ταμείο και την Ελλάδα (Ερευνητικό πρόγραμμα «Αριστεία»). Στόχος της ημερίδας ήταν η συζήτηση και ο προβληματισμός για τις βασικές αρχές και τις ορθές πρακτικές που αφορούν στη συγκρότηση διαχρονικών σωμάτων κειμένων με σκοπό τη γλωσσολογική έρευνα. Η εμπειρία μελετητών που έχουν εργαστεί σε σχετικά ερευνητικά προγράμματα σε άλλες γλώσσες αναμένεται να συμβάλει σημαντικά στη διαμόρφωση των στόχων και των πρακτικών του διαχρονικού σώματος κειμένων της Ελληνικής, καθώς, σε αντίθεση με άλλες γλώσσες, η Ελληνική δεν έχει επωφεληθεί έως τώρα από την ανάπτυξη της υπολογιστικής γλωσσολογίας σωμάτων κειμένων στο βαθμό που θα αναμενόταν: η έλλειψη ενός διαχρονικού σώματος κειμένων της Ελληνικής αποτελεί ένα μείζον κενό στην ελληνική γλωσσολογία και το ερευνητικό πρόγραμμα στοχεύει να καλύψει αυτό το κενό, αναπτύσσοντας ένα σώμα κειμένων 20 εκατ. λέξεων για τις πρώτες εννέα δεκαετίες του 20ου αιώνα, το οποίο θα ενσωματωθεί στο προϋπάρχον σώμα κειμένων 30εκατ. λέξεων του ΣΕΚ. Στόχος του σώματος κειμένων είναι η μελέτη περιοχών πρόσφατης γλωσσικής αλλαγής (τόσο σε γραμματικό όσο και σε λεξιλογικό επίπεδο) μέσω της ανάλυσης αυθεντικών κειμένων.
Ο Mark Davies είναι Καθηγητής Γλωσσολογίας στο Brigham Young University στη Γιούτα των ΗΠΑ. Αποφοίτησε με πτυχίο Γλωσσολογίας και Ισπανικής Γλώσσας και πήρε μεταπτυχιακό δίπλωμα στην Ισπανική Γλωσσολογία από το Brigham Young University και διδακτορικό από το Πανεπιστήμιο του Τέξας στο Austin με ειδίκευση στην ιβηρο-ρομανική γλωσσολογία. Έχει διδάξει στο Πανεπιστήμιο Illinois State (1992-2003) και στο Πανεπιστήμιο Brigham Young (από το 2003). Η έρευνά του αφορά την ιστορική και κειμενική ποικιλότητα στη σύνταξη της Ισπανικής και Πορτογαλικής, το σχεδιασμό και τη δημιουργία σωμάτων κειμένων, τη χρήση σωμάτων κειμένων (ιδίως της Αγγλικής) και την ανάλυση της συχνότητας και των συνάψεων σε σώματα κειμένων. Τα βιβλία του περιλαμβάνουν: A Frequency Dictionary of American English (2010, με την D. Gardner), Corpus Linguistic Applications: Current Studies, New Directions (2009 επιμ. με τους S. Gries και S. Wulff), A Frequency Dictionary of Portuguese (2007, με την A. M. Raposo Preto-Bay) και A Frequency Dictionary of Spanish (2005). Έχει αναπτύξει πολλά σώματα κειμένων, μεταξύ των οποίων το Corpus of Global Web-Based English με 1,9 δισεκατομμύρια λέξεις, Google Books Corpus με 155 δισεκατομμύρια λέξεις, το Corpus of Historical American English με 400 εκατομμύρια λέξεις, Corpus of Contemporary American English (COCA) 450 εκατ. λέξεων, το Corpus del Español 100 εκατ. λέξεων, το Corpus do Português 45 εκατ. λέξεων κ.ά.



: Issues of design and compilation")