





















Βεργύρη Δήμητρα
Γλώσσα
Αγγλική
Ημερομηνία
20/12/2018
Διάρκεια
00:52:34
Εκδήλωση
IEEE SLT 2018 | Workshop on Spoken Language Technology
Χώρος
Ξενοδοχείο Royal Olympic
Διοργάνωση
IEEE
Κατηγορία
Τεχνολογία
Ετικέτες
spoken language technology, Gaussian Mixing Models, Deep Neural Networks, Speech-In-The-Wild Analytics, τεχνολογίες ομιλίας, ανάλυση ομιλίας, ανίχνευση ομιλίας
Speech-In-The-Wild Analytics στην εποχή της βαθιάς μάθησης: Πρόσφατες εξελίξεις και εναπομένουσες προκλήσεις.
Κατά την τελευταία δεκαετία, η βαθιά μάθηση έχει εξαπλωθεί σε όλους τους τομείς της επεξεργασίας ομιλίας και γλώσσας και έχει οδηγήσει σε μεγάλες βελτιώσεις στην ευχρηστία των εφαρμογών ομιλούμενης γλώσσας. Παρ' όλα αυτά, περιβάλλοντα με πρωτοφανείς ή ιδιάζουσες συνθήκες παραμένουν μια πρόκληση για αυτή την τεχνολογία.
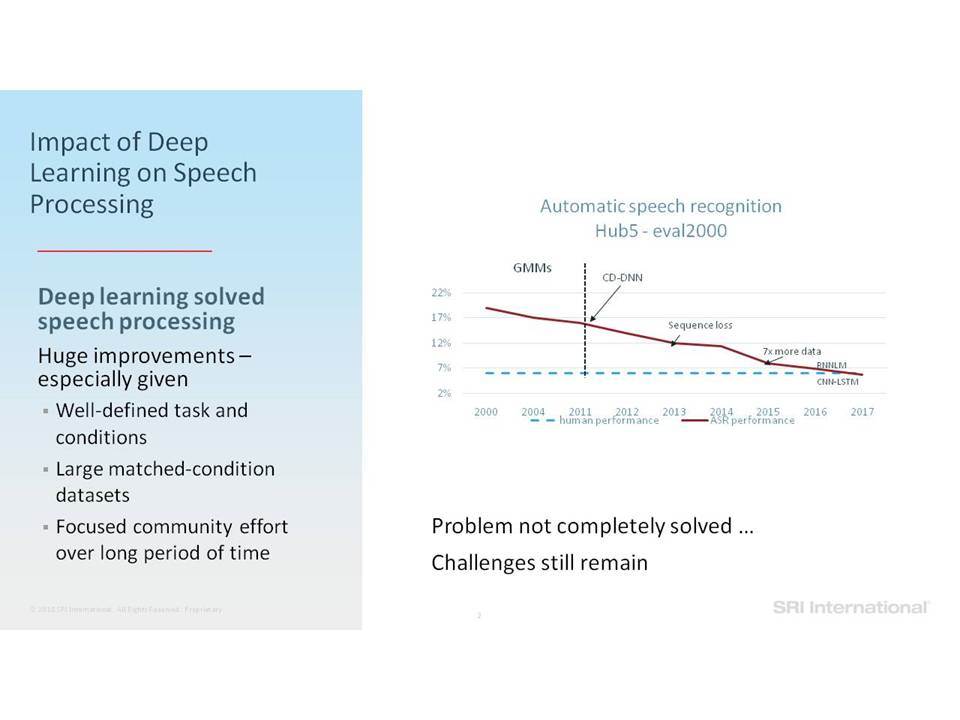
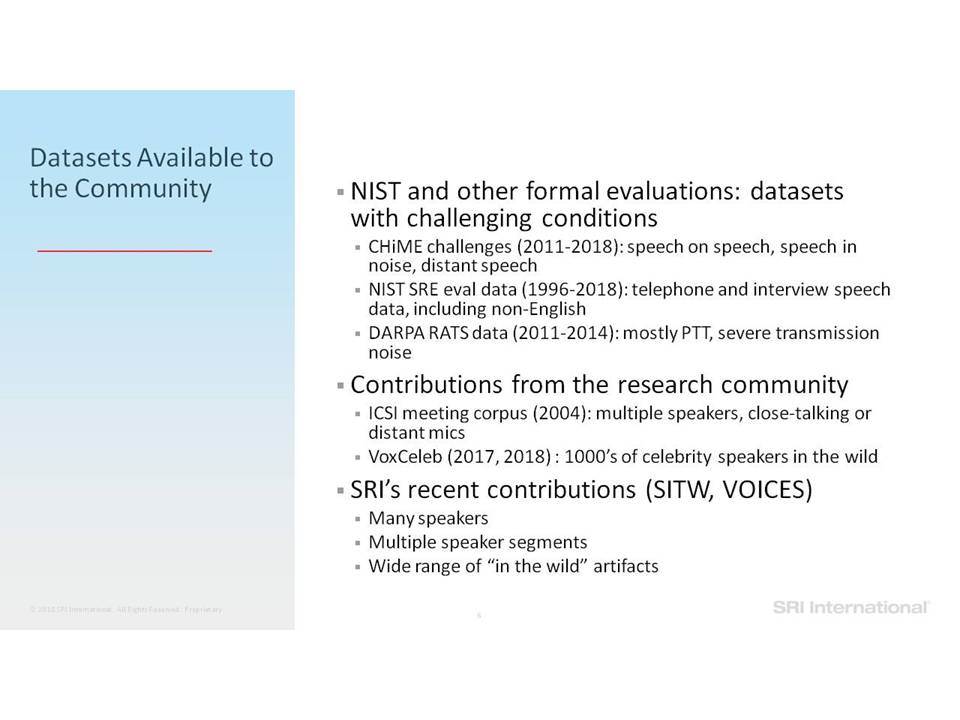
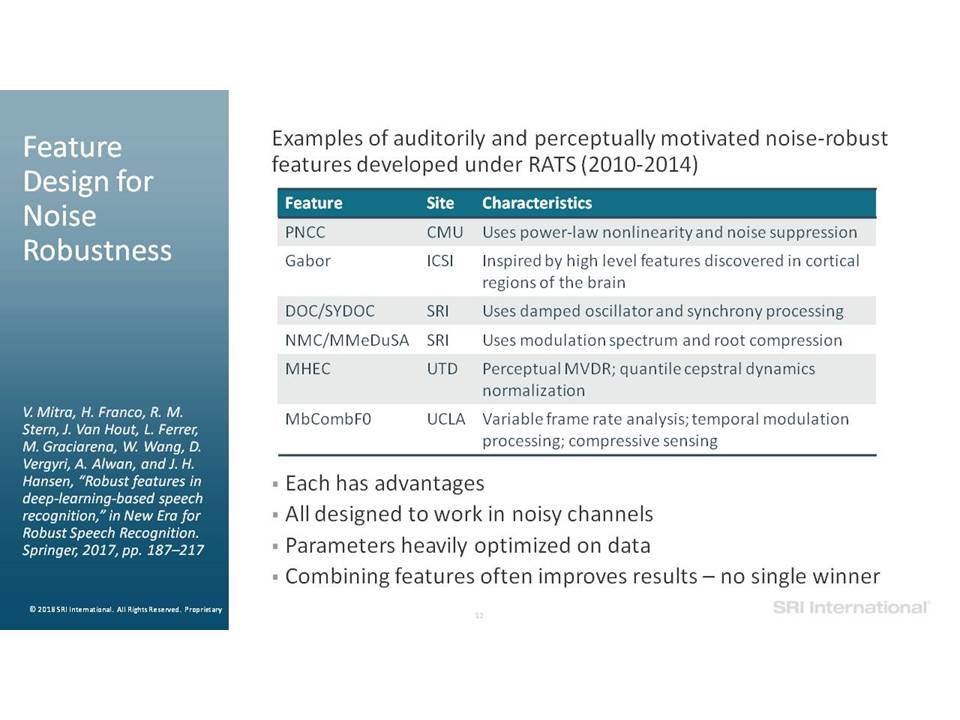
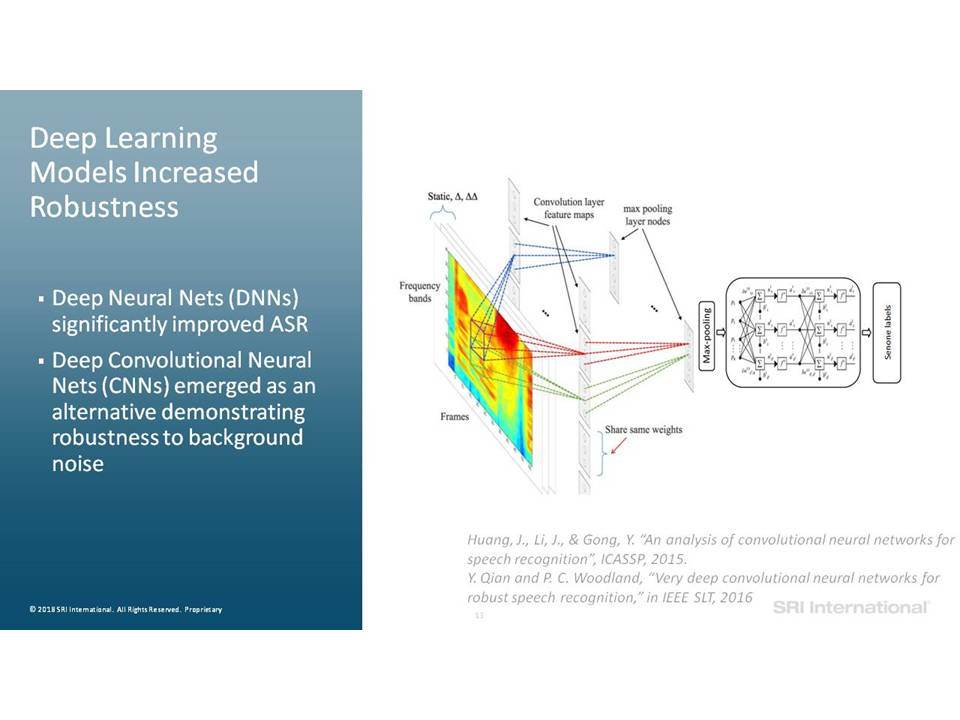
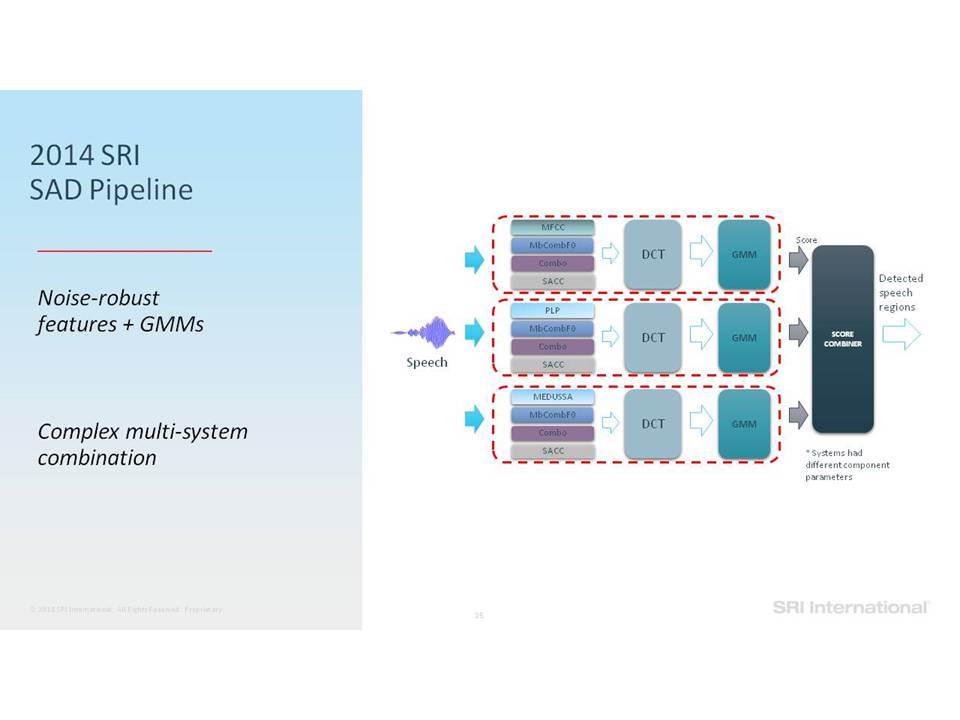
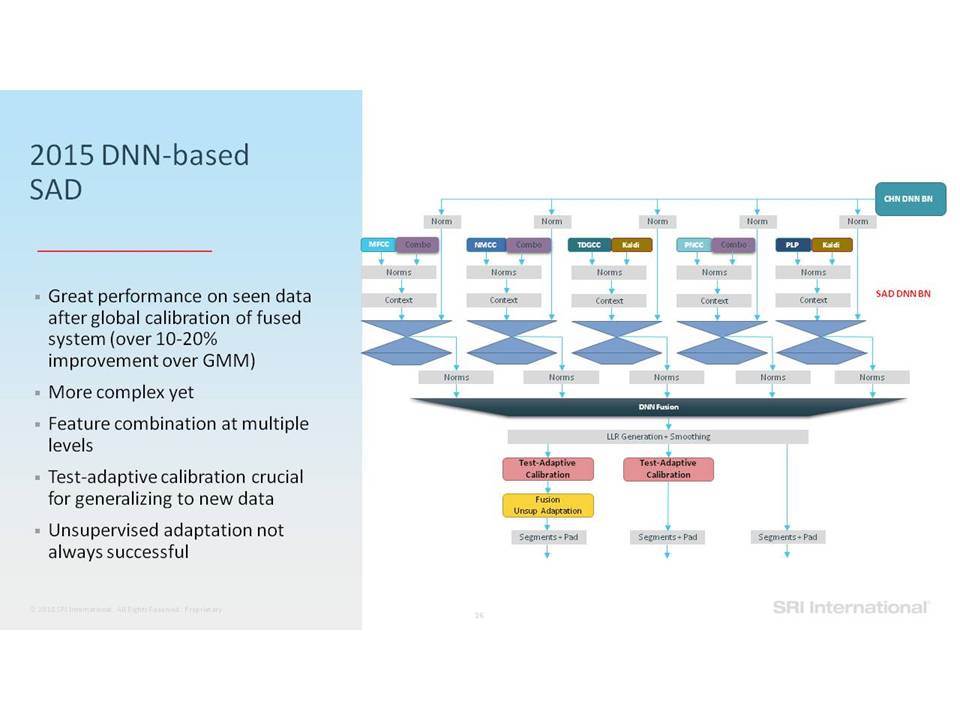
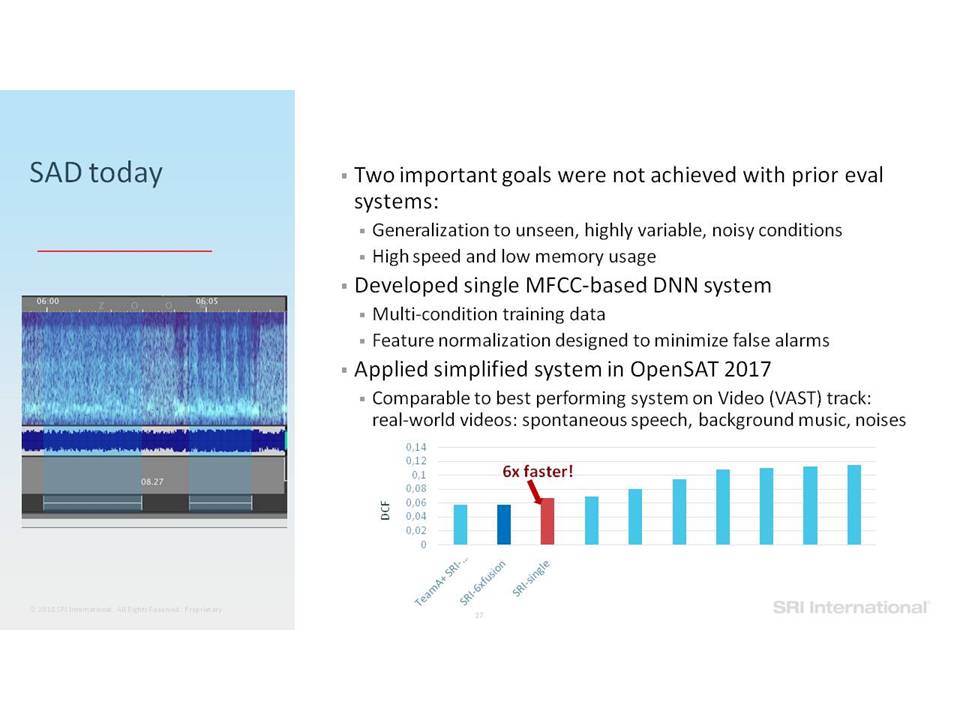
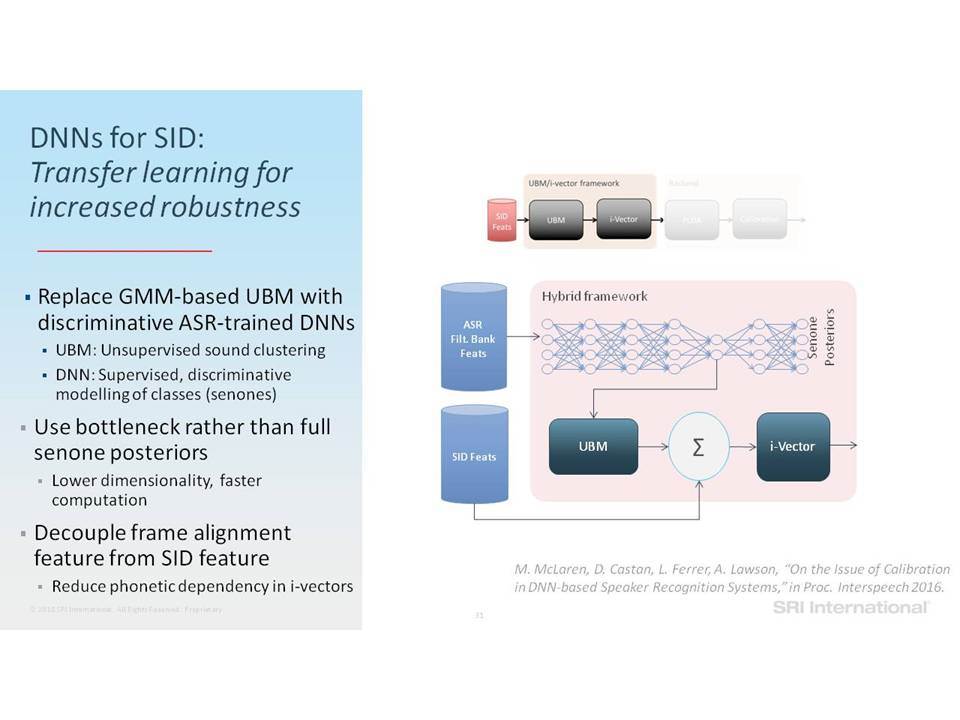
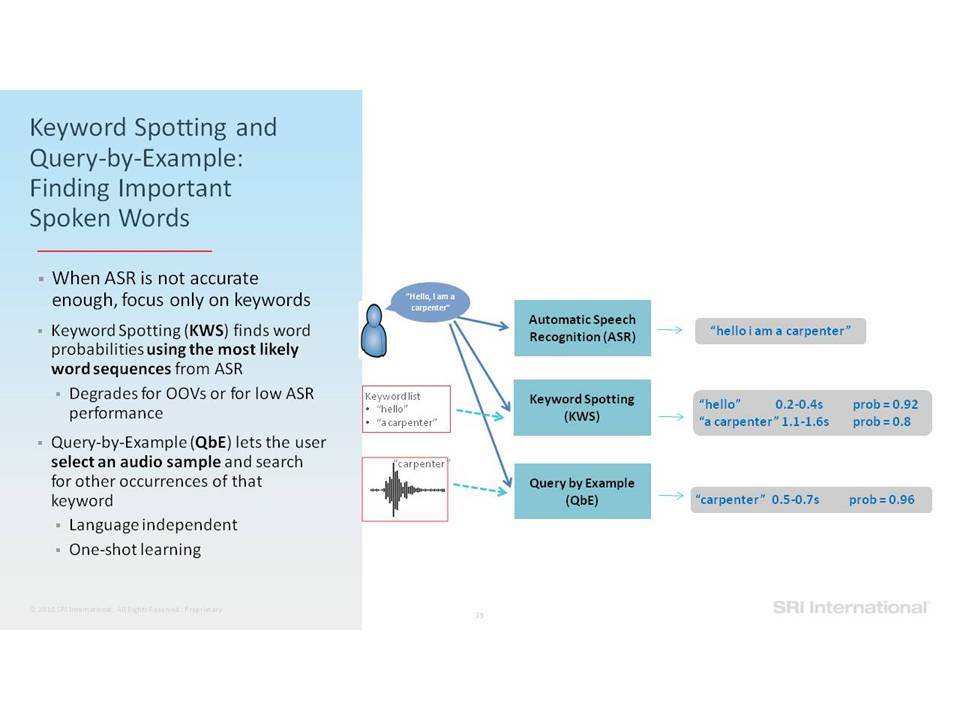
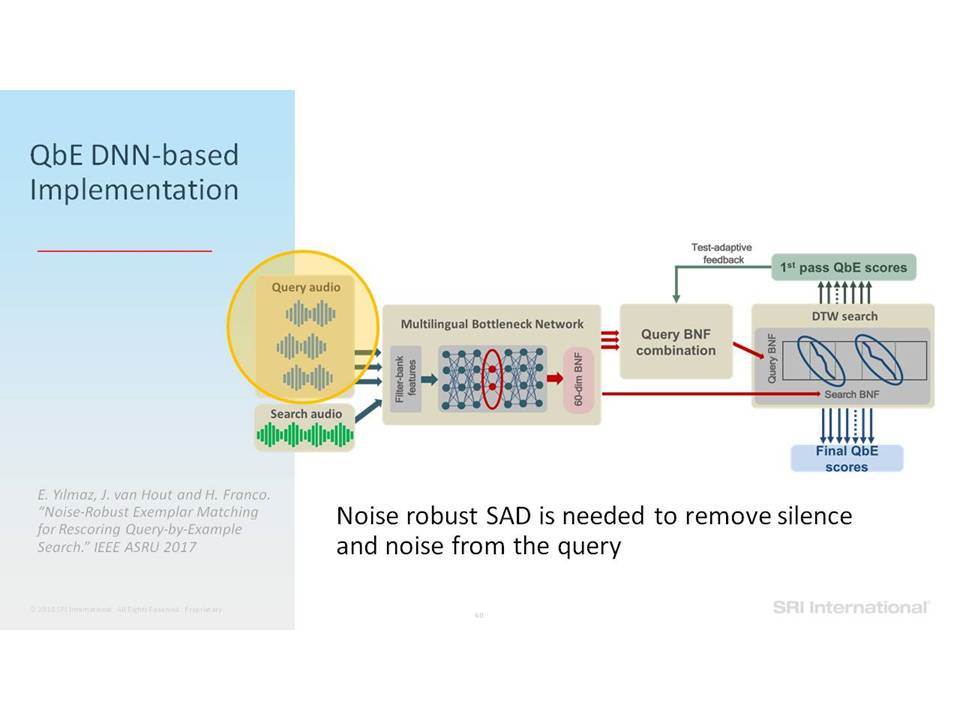
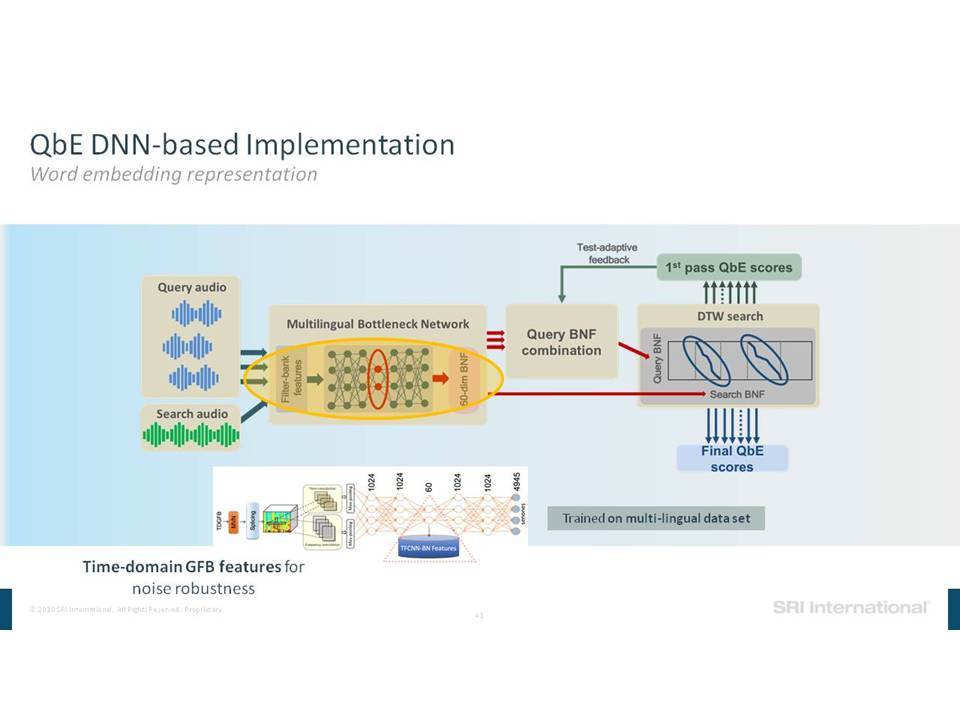
Σε αυτή την ομιλία επικεντρωνόμαστε σε εργασίες ανάλυσης της ομιλίας που περιλαμβάνουν την ανίχνευση ομιλίας, την αναγνώριση ομιλητών και τον εντοπισμό λέξεων-κλειδιών. Ειδικότερα, εστιάζουμε στην επεξεργασία της ομιλίας “in the wild”, η οποία περιλαμβάνει δεδομένα σε φυσικό περιβάλλον, που συχνά δεν ανταποκρίνονται στις συνθήκες εκπαίδευσης, παρουσιάζουν εσωτερική (από την πλευρά του ομιλητή) και εξωγενή (από την πλευρά του περιβάλλοντος) μεταβλητότητα και υποβάθμιση λόγω π.χ. της απόστασης από το μικρόφωνο, τον θόρυβο της μετάδοσης, εφέ των καναλιών, κωδικοποιήσεις που παρουσιάζουν απώλειες και άλλα στοιχεία που οφείλονται στο περιβάλλον (environmental artifacts). Επισημαίνουμε βελτιώσεις στην επίδοση της ανάλυσης σε τέτοια δεδομένα, καθώς η τεχνολογία μετακινήθηκε από τη χρήση Gaussian Mixing Models (GMMs) σε Deep Neural Networks (DNNs) και πέρα από αυτά, καθώς και από τη χρήση επεξεργασίας σημάτων που παρουσιάζει ανοχή σε θόρυβο και i-vectors μέχρι και embeddings.
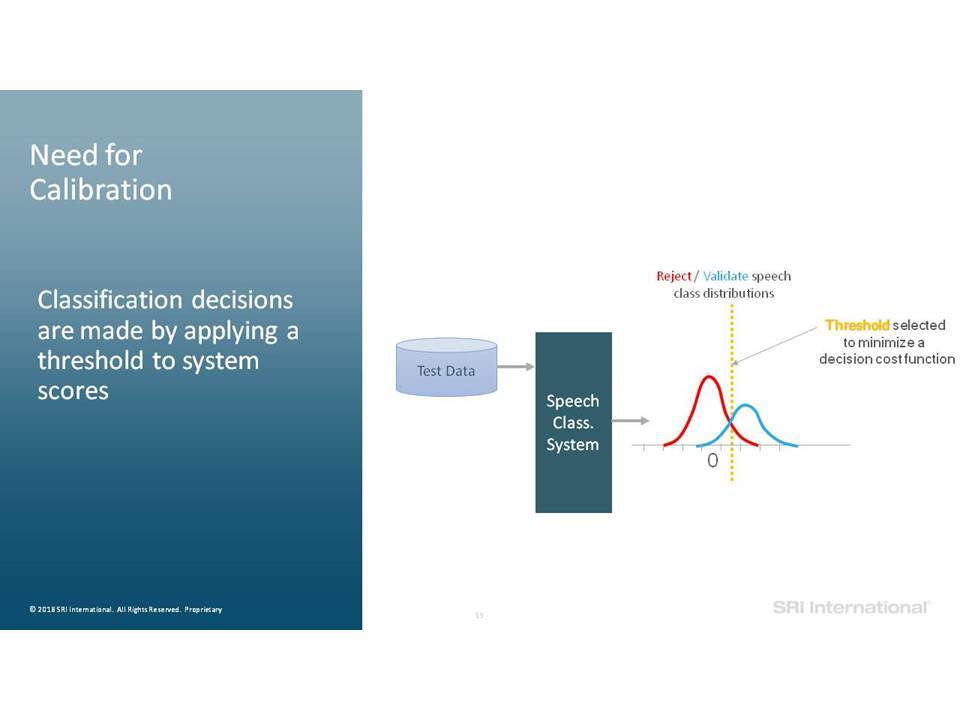
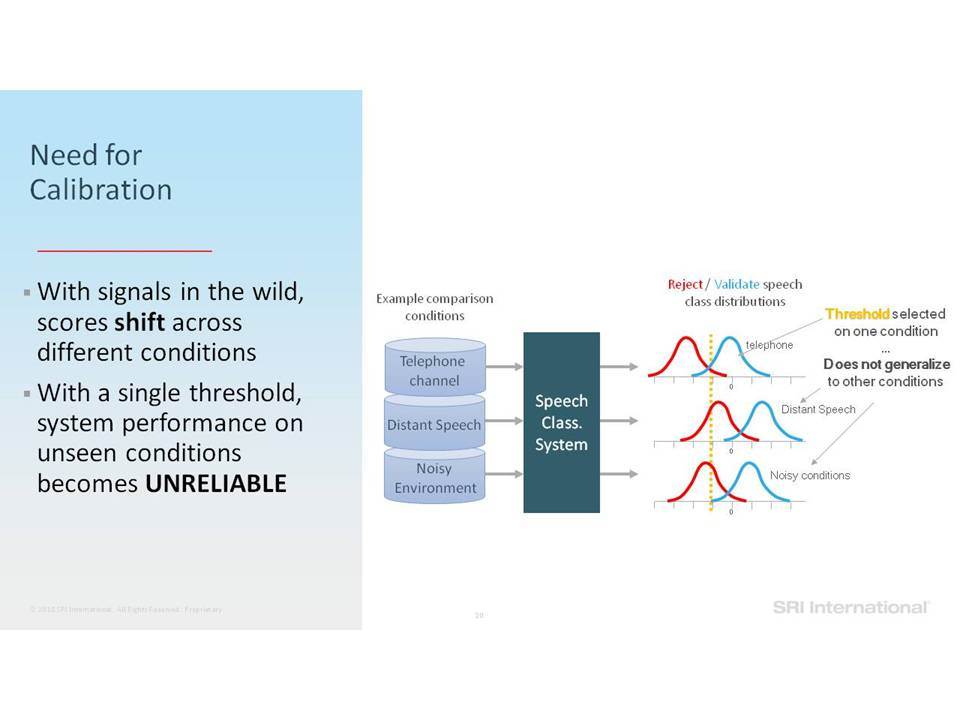
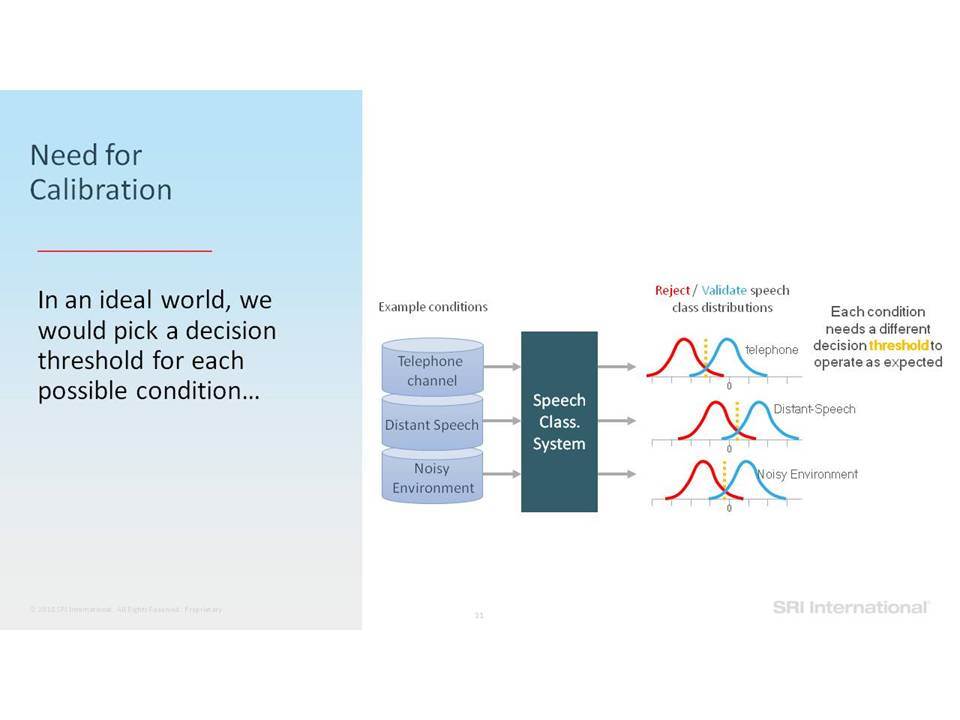
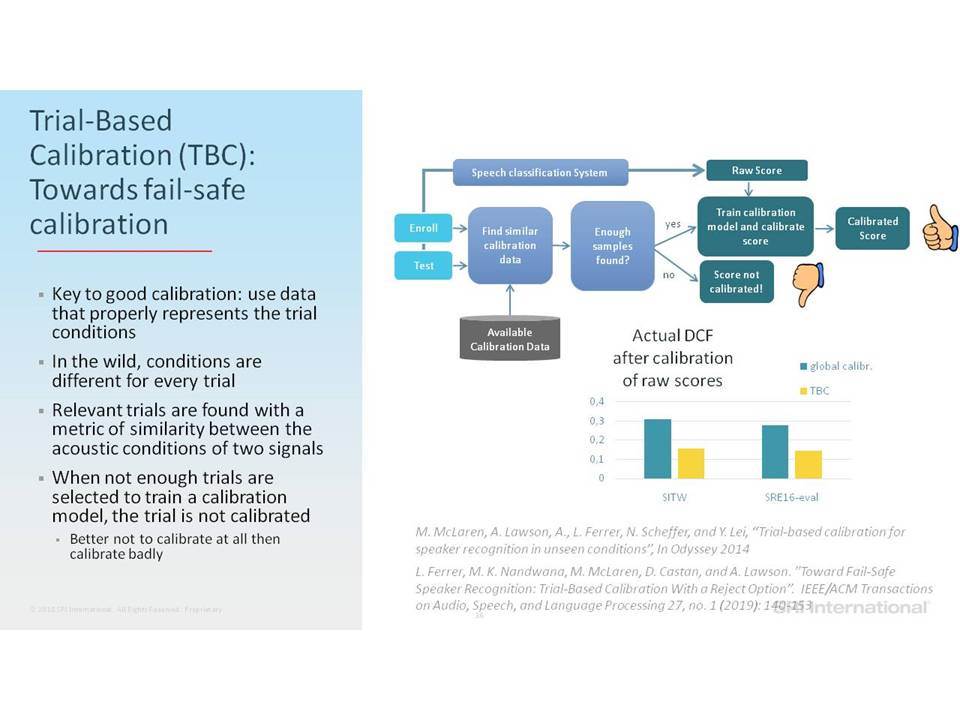
Για όλες τις εργασίες ταξινόμησης ομιλίας που περιγράφονται, είναι σημαντικό να γνωρίζετε πότε να εμπιστεύεστε ότι εξάγεται από το σύστημα, ειδικά σε διαφορετικές, απρόσμενες συνθήκες εισαγωγής δεδομένων και σήματα ομιλίας μικρής διάρκειας. Η επιτυχής βαθμονόμηση βαθμολογίας μοντέλου (model score calibration) αποτελεί βασική πρόκληση για τη χρήση των συστημάτων σε δεδομένα που αφορούν την ομιλία σε κατάσταση in-the-wild. Θα εξετάσουμε τον αντίκτυπο της βαθμονόμησης και θα συζητήσουμε τις πρόσφατες εξελίξεις των αλγορίθμων βαθμονόμησης.
Η ομιλία καλύπτει ερευνητικές συνεισφορές από μέλη και πρώην μέλη του εργαστηρίου STAR της SRI International, συμπεριλαμβανομένων των Mitchell McLaren, Horacio Franco, Martin Graciarena, Aaron Lawson, Diego Castan, Mahesh Nandwana, Julien Van Hout, Colleen Richey, Luciana Ferrer (UBA-CONICET ) και Vikramjit Mitra (Apple / UMD).
Speech-In-The-Wild Analytics in the Era of Deep Learning: Recent Advancements and Remaining Challenges
During the last decade, deep learning has spread in all areas of speech and language processing and has led to big improvements in the usability of the spoken language technology applications. Nevertheless, unseen and mismatched data conditions remain a challenge for this technology.
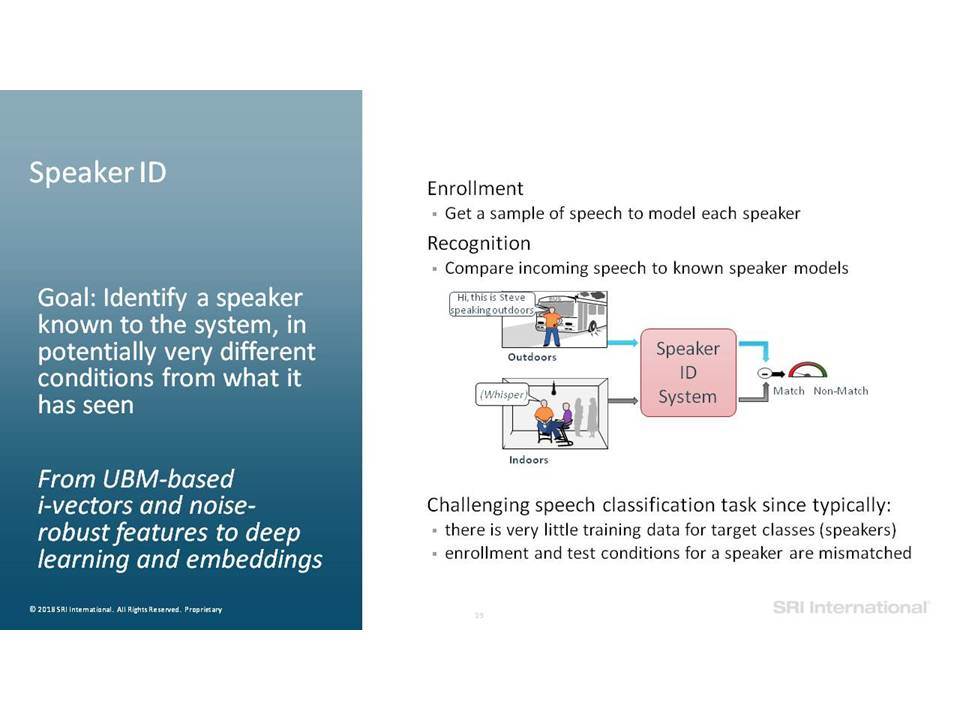
In this talk we focus on speech analytics tasks that include speech detection, speaker identification and keyword spotting. More specifically we focus on processing speech “in the wild”, which includes data in natural environments, often mismatched to training conditions, exhibiting intrinsic (speaker) and extrinsic (environmental) variability and degradation due, for example, to distance from microphone, transmission noise, channel effects, lossy encodings and other environmental artifacts. We highlight improvements on such data as the technology moved from using Gaussian Mixture Models (GMMs) to Deep Neural Networks (DNNs) and beyond, and from using noise-robust signal processing and i-vectors to embeddings.
For all described speech classification tasks, it is important to know when to trust the system output, especially in varying, unexpected input conditions and short duration speech signals. Successful model score calibration is a key challenge in using the systems on speech-in-the-wild data. We will review the impact of calibration and discuss recent advancements of calibration algorithms.
The talk covers research contributions from current and past members of the STAR laboratory at SRI International, including Mitchell McLaren, Horacio Franco, Martin Graciarena, Aaron Lawson, Diego Castan, Mahesh Nandwana, Julien Van Hout, Colleen Richey, Luciana Ferrer (UBA-CONICET) and Vikramjit Mitra (Apple/UMD).
Η Δήμητρα Βεργύρη είναι Διευθύντρια του Εργαστηρίου Τεχνολογιών Ομιλίας και Έρευνας (STAR - Speech Technology and Research Laboratory) στο Ερευνητικό Ινστιτούτο SRI στις ΗΠΑ. Η ομάδα της ηγείται ερευνητικών έργων και μεταφέρει τεχνολογία στους πελάτες, αντιμετωπίζοντας ανάγκες επεξεργασίας ομιλίας σε περιβάλλοντα με θόρυβο, αναγνώριση ομιλίας, αναγνώριση ομιλητή και γλώσσας, μετάφραση ομιλίας, προφορικά συστήματα διαλόγου, γλωσσική εκπαίδευση, ανάλυση λόγου και πολλά άλλα. Έλαβε το πτυχίο Ηλεκτρολόγου Μηχανικού και Μηχανικού Υπολογιστών από το Εθνικό Μετσόβιο Πολυτεχνείο, Ελλάδα το 1993, ενώ ολοκλήρωσε Μεταπτυχιακές και Διδακτορικές σπουδές στο Πανεπιστήμιο Johns Hopkins, ΗΠΑ το 1995 και το 2000 αντίστοιχα. Το 2000 εντάχθηκε στην SRI International, όπου εργάστηκε σε πολλά ερευνητικά έργα και δημοσίευσε πάνω από 50 επιστημονικές εργασίες στους τομείς της εξαγωγής πληροφορίας από ομιλία, της φωνητικής ανάλυσης για συναισθηματική και γνωστική αξιολόγηση, της αναγνώρισης ομιλίας με περιορισμένα δεδομένα εκπαίδευσης, της πολυγλωσσικής ηχητικής αναζήτησης και μηχανικής μετάφρασης. To 2010 είχε θέση επισκέπτη ερευνητή στο LIMSI / CNRS, ενώ από το 2015 υπηρετεί ως Διευθύντρια του εργαστηρίου STAR. Από το 2009 έως το 2012 υπήρξε συνεργαζόμενη συντάκτρια του επιστημονικού περιοδικού IEEE Transactions on Audio Speech and Language Processing. Έχει συμμετάσχει σε πολυάριθμες επιτροπές αναθεώρησης και διοργάνωσης συνεδρίων καθώς και τεχνικών επιτροπών.
Her group is leading research projects and is transferring technology to clients, addressing needs for speech processing in noisy environments, speech recognition, speaker and language identification, speech translation, spoken dialog systems, language education, speech analytics, and more. She received her diploma in Electrical and Computer Engineering from the National Technical University of Athens, Greece, in 1993, and Masters and Ph.D degrees from Johns Hopkins University, in 1995 and 2000 respectively. In 2000 she joined SRI International where she worked on multiple research projects and published over 50 papers in the areas of information extraction from speech, voice analysis for emotional and cognitive assessment, speech recognition with sparse training data, multilingual audio search, and machine translation. She had a visiting position in LIMSI/CNRS in 2010 and is serving as the Director of the STAR lab since 2015. From 2009-2012 she also served as an associate editor for the IEEE Transactions on Audio Speech and Language Processing. She has participated in multiple reviewing panels and conference organizing and technical committees.
